Thread #108006860 | Image & Video Expansion | Click to Play


/lmg/ - a general dedicated to the discussion and development of local language models.
Previous threads: >>107997948 & >>107986301
►News
>(01/28) Trinity Large 398B-A13B released: https://arcee.ai/blog/trinity-large
>(01/27) Kimi-K2.5 released with vision: https://hf.co/moonshotai/Kimi-K2.5
>(01/27) DeepSeek-OCR-2 released: https://hf.co/deepseek-ai/DeepSeek-OCR-2
>(01/25) Merged kv-cache : support V-less cache #19067: https://github.com/ggml-org/llama.cpp/pull/19067
>(01/22) Qwen3-TTS (0.6B & 1.8B) with voice design, cloning, and generation: https://qwen.ai/blog?id=qwen3tts-0115
>(01/21) Chroma-4B released: https://hf.co/FlashLabs/Chroma-4B
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting-started-guide
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWebService
https://rentry.org/recommended-models
https://rentry.org/samplers
https://rentry.org/MikupadIntroGuide
►Further Learning
https://rentry.org/machine-learning-roadmap
https://rentry.org/llm-training
https://rentry.org/LocalModelsPapers
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/gso.html
Context Length: https://github.com/adobe-research/NoLiMa
GPUs: https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngla98yc
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
Sampler Visualizer: https://artefact2.github.io/llm-sampling
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-generation-webui
https://github.com/LostRuins/koboldcpp
https://github.com/ggerganov/llama.cpp
https://github.com/theroyallab/tabbyAPI
https://github.com/vllm-project/vllm
360 RepliesView Thread
 Showing all 360 replies.
Showing all 360 replies.>>
File: __hatsune_miku_vocaloid_drawn_by_zeon_zzeeonn__7c20859ba4a93c814f83e5153449882f.jpg (553.1 KB)

553.1 KB JPG
►Recent Highlights from the Previous Thread: >>107997948
--Papers:
>107999601 >107999634
--GPU offloading tradeoffs and multimodal support in llama.cpp:
>107999073 >107999192 >107999228 >107999351 >107999408 >107999434 >107999437 >108000983 >108001095 >108001101 >108001152 >108001289 >108001475 >108001533 >108001553 >108001566 >108001612 >108001633 >107999250 >107999287 >107999301 >107999423 >108001903 >108001981
--Stable-DiffCoder-8B benchmark performance and discussion on diffusion model efficiency:
>108001010 >108001106 >108001620 >108001109 >108001172 >108001216 >108004118 >108004176 >108004237 >108004283 >108004343
--Trinity model's explicit content generation and token prediction comparisons:
>107999802 >108000348 >108000369 >108001448 >108001514 >108001792 >108002123 >108002142 >108002336 >108002598
--Fine-tuning 400B MoE for roleplay with long context using novel datasets:
>108001139 >108001164 >108001185 >108001319 >108001402 >108003532 >108003598 >108003946 >108003968
--Repurposing old GPUs with PCIe expansion board for multi-GPU AI setups:
>107998221 >107998260 >107999172
--Pipeline for converting scanned PDFs to EPUB with graph handling:
>107999667 >108000337 >108001320
--SillyTavern fork adds banned strings and regex support with TFS:
>108000166 >108000735 >108000921 >108002916
--Local GPU setups vs cloud:
>107998010 >107998028 >107998070 >107998115 >107998232 >107998263 >107998279 >107998376 >107998408 >107998428 >107998492 >107998095 >107998132 >107998454 >107998675
--400B Trinity model enables uncensored erotica without fine-tuning or ablation:
>108003672 >108004704 >108004713 >108004829 >108004839 >108004872 >108004874 >108004869 >108004898 >108004913 >108005031
--Mozilla's AI "rebel alliance" with ethics-focused funding:
>108004243 >108004266
--Miku (free space):
>107998400 >107999172 >108003297 >108004558
►Recent Highlight Posts from the Previous Thread: >>107997953
Why?: >>102478518
Enable Links: https://rentry.org/lmg-recap-script
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
File: 24352345.png (121 KB)

121 KB PNG
>read something about cloudflare downtime caused by rust .unwrap function which caused a shitstorm
>whatever
>fast forward to today, I'm vibegooning some open source rust project because I cba learning the language
>LLM puts .unwrap almost everywhere
goncerning :DDddd
>>
>>
>>
File: 1769731385067_6836444524742047.png (1.1 MB)

1.1 MB PNG
>>108007291
Well, here's a page I had both transcribe and here were the results:
Qwen VL 235B Instruct (Using Poe):
Narration: そして
勇者は冒険の末
魔王を倒した
Male 1: それで
クレアナ
話って
なんなの?
こんな
森の奥まで
呼び出して…
こちらです
Female 1: これからの
平和な世の中が
始まるね!
そうですね…
勇者ライ様の
おかげで
世に平和が
戻りました
Male 1: な、何を
するんだ!?
Female 1: 勇者様…
私と教団は勇者様の
意思は絶対と女神に
神託を受け従って
まいりました…
Male 1: 洞窟?
Female 1: うわっ
And here is K2.5 using the NVdia API:
Narration: そして勇者は冒険の末魔王を倒した
Male 1: これからは平和な世の中が始まるね!
Female 1: そうですね…勇者ライ様のおかげで世に平和が戻りました
Male 1: それでクレアナ
Male 1: 話ってなんなの?
Male 1: こんな森の奥まで呼び出して…
Female 1: こちらです
Male 1: 洞窟?
Male 1: うわつ
Male 1: いてつ
Male 1: な、何をするんだ!?
Female 1: 勇者様…私と教団は勇者様の意思は絶対と女神に神託を受け従ってまいりました…
Male 1: ?
Seems pretty obvious which one won.
>>
>>
File: 1768676727095338.png (21.5 KB)

21.5 KB PNG
>>108007380
dond worry :DD rusd is memory safe so ids ok :DDDDD
>>
File: 1763610739922873.gif (186 KB)

186 KB GIF
>>108007797
how did gondola survive but not the original
>>
File: lol.png (129.7 KB)

129.7 KB PNG
> Microsoft lost $357 billion in market cap as stock plunged most since 2020
> Analyst Ben Reitzes of Melius Research, with a buy rating on Microsoft stock, said during CNBC’s “Squawk on the Street” on Thursday that Microsoft should double down on data center construction.
> “I think that there’s an execution issue here with Azure, where they need to literally stand up buildings a little faster,” he said.
> Analysts at UBS led by Karl Keirstead questioned Microsoft’s choice to secure artificial intelligence computing capacity for products such as the Microsoft 365 Copilot productivity software add-on that has yet to succeed as much as OpenAI’s ChatGPT.
> “M365 revs growth is not accelerating due to Copilot, many checks on Copilot don’t suggest a strong usage ramp (we plan to refresh our own checks in case we’ve missed a usage ramp) and the model market appears crowded and capital-intensive,” the UBS analysts wrote. “We think Microsoft needs to ‘prove’ that these are good investments.”
https://www.cnbc.com/2026/01/29/microsoft-market-cap-earnings.html
>>
>>
>>
>>
>>
>>108008167
Raptor-0112. I couldn't tell if it was because it was brain-damaged or what, but it was the only one that really surprised me when it came to word choice and additions to the plot. It came up with some stuff that wasn't in the prompt, but kept with the tone and felt like it added to it.
>>
>>
>>
>>108007061
>distill from claude 4.5 opus
I think they did, just based on swapping opus->k2.5 and regenerating. It takes RP in similar directions. Opus doesn't waste time on safety check though.
>how good is this anons?
Tried it when it came out. Forgets instructions after a few turns. Even the example about never using python or whatever they said it could do.
>>
>>
File: 1766528709009119.jpg (119.7 KB)

119.7 KB JPG
Kind of noob here. Sorry in advance for the long-winded question. I have 24gb of vram and 64gb of ram. I was under the impression that of all the models out there, the best model in terms of world knowledge and general usefulness while maintaining usable speed is gpt-oss-120b-mxfp4 gguf (if I offload experts to cpu and max out the gpu layers, I can get 25+ tok/s if i keep the context small; prompt processing gets very slow as the context fills though unfortunately). However, I don't see it anywhere on the rentry for recommended models. Is there a reason for that? are the models listed there better options for general use? quen3 32b or gemma3 27b for example.
Separate from that question, I notice when I'm using gpt-oss-120b in oobabooga with the built-in/default instruction template and parameters, the output tends toward annoying behaviors that I don't like. For example, putting every answer into a poorly-formatted table even when it's completely unnecessary and I didn't ask for one. It makes me think that I'm using the wrong settings somehow, but idk what to change because the official documentation doesn't really say how to set the parameters so I have it set to the "instruct" preset, and the UI for the instruction template says "This gets autodetected; you usually don't need to change it." And I assume I should be using instruct mode, right?
>>
>>
>>108006860
Ok, go with me on this for a second.
Today's AI is retarded at certain things, but has technological possibility advantages over real life retards. Now, hear me out.
Imagine if you could give a real life retard, full fidelity photographic memory.
Boom. Suddenly, that guy is the smartest retard on the planet.
Ok, so... There's a functional jump for this. With real life AI.
We are all going to be doing this, very soon.
"Photographic" introspection.
A cache hypervisor that allows the model to save states, of KV cache, as it iterates a query, during the thinking stages, it can instantly consult save states, with a hypervisor to the cache, that is an algorithm to save cache windows in full, and reproduce them near instantly.
During iteration, being able to factor in a secondary branch, using previous memory states, could accelerate the state of AI thought output, and cut down on wasted iterative thoughts.
Predictive branching needs to work in more directions than just the future, if the initial query was misunderstood or must be used as an additional consideration input. (Artificially creating weight value changes, based on a repeat of existing data.) Why... To get it to recursively improve this system, you may even have to say, let the iterative count of previous memory pulls in the algorithm be a recorded factor, and allow the AI to manage it's own shadow weights.
All of this is possible, by using the same tech we've had since the dawn of the Super Nintendo Emulator, but applied at the cache management level.
(Save states.)
Then use an AI to manage the utilization of the cache save state algorithm.
After a minor amount of inference training...
You could have the most accurate retard in a box, out of anybody around.
>>
File: file.png (225.6 KB)

225.6 KB PNG
Any other model for computer stuff? For a 16GB GPU? Qwen3-Coder seems alright but I want to try something newer, also I am having fun with this stuff, already switched to llamacpp from ollama .
>>
>>
>>
>>108008408
Holy shit, someone who actually read the sticky.
>Is there a reason for that?
If I had to take a guess it's because of the general dislike towards the gpt oss models due to the censorship and refusals. If it works for your usecase, I recommend you stick with it.
>ooba.
Go to the parameters tab and take a look at the instruction template after you've loaded a model. It should show you the correct template. You can cross reference it with the chat template on the huggingface repo of the model you are using to double check. Your issue is likely a sampler or prompt issue. I'm not quite sure what the optimal parameters are for your use case, but I like to run:
>temp 1
>min_p 0.05
>top_p 1
>dry_multiplier 0.8
for ERP and creative. Lower Temp for coding.
>>
>>
File: myretard.png (277.6 KB)

277.6 KB PNG
>>108008503
Here's what my actual retard thinks of that.
>>
>>108008503
Functionally, here me out and really consider this at a technical level.
How big is a super Nintendo game save state file? It records the full exact moment of the game, but the file is tiny.
Of such size, that if we were talking RAM cache (GPU VRAM or otherwise), this level of data management seems trivial, and in the right ballpark of working for states of cache chunks.
Now, the tricky part of this, is trying to make an algorithm that handles variable sizes for the cache chunks, so this can work with anything.
Which is why a successful implementation of this, would have to start as a hypervisor or manager that works seamlessly with the existing cache management, to not lose performance at the cost of having memory states available on the fly, as controlled within cache.
(I'm suggesting running this whole thing, in-situ, btw. If it runs within the cache itself, will be fastest returns on whether this works or not, and allow scaling.)
Emulator code is out there, I'm sure this could fit as a running sub-Daemon or something.
Figuring out the triggers for whether a "flashback" is the right call or not.
Hmm... That's what I think would take some inference time.
>>
>>108008580
preview is an instruct version, which is for chatting rather than text completion. true base is a heavily filtered variant of the normal base, which means it will be less optimal for text completion due to a lack of knowledge. the only reason true base exists is if you wanted to make your own custom instruct version of the model.
>>
>>
>>
>>108008603
I see, thanks. Well for now there doesn't seem to be base gguf quants available.
So I want to get the instruct version as a first quick test, but I'm completely unable to download anything outside of the last shard :
https://huggingface.co/arcee-ai/Trinity-Large-Preview-GGUF/tree/main/T rinity-Large-Preview-IQ2_S
2 of 3 give me 403 and I'm not sure why. Anyone else can test that?
>>
>>108008624
Enabling any human to have full fidelity reference to past memory states, would make them seem like a functional genius in modern society, even if this did not directly raise their IQ at all.
It is a functional cognitive enablement, that we can make for AI, but can not perform for ourselves.
Full fidelity memory reference, would be a super power to a human thinker.
Copy pasting data is trivial, the management is the hard part, but once executed, this should give it some capability improvement.
>>
>>108008645
just tried to download that gguf and i also got the same error. think it might be a broken file or something.
technically you can create your own ggufs for these models, you just need to download the fp16 of the model and use the llama-quantize tool. the architecture has been supported by llama.cpp for like half a year now
>>
File: myretard2.png (171.2 KB)

171.2 KB PNG
>>108008607
So my retard is very experimental.
It's biased towards trying to map high-level concepts into the real computer science. And all the RLHF'd enthusiasm / "you're absolutely right" concepts have been completely removed.
What I mean is, don't let it discourage you if you're building something.
>>
>>108008645
Yes, those are broken. Same for me yesterday.
Get them from here: https://huggingface.co/bartowski/arcee-ai_Trinity-Large-Preview-GGUF/t ree/main
>>
File: file.png (126 KB)
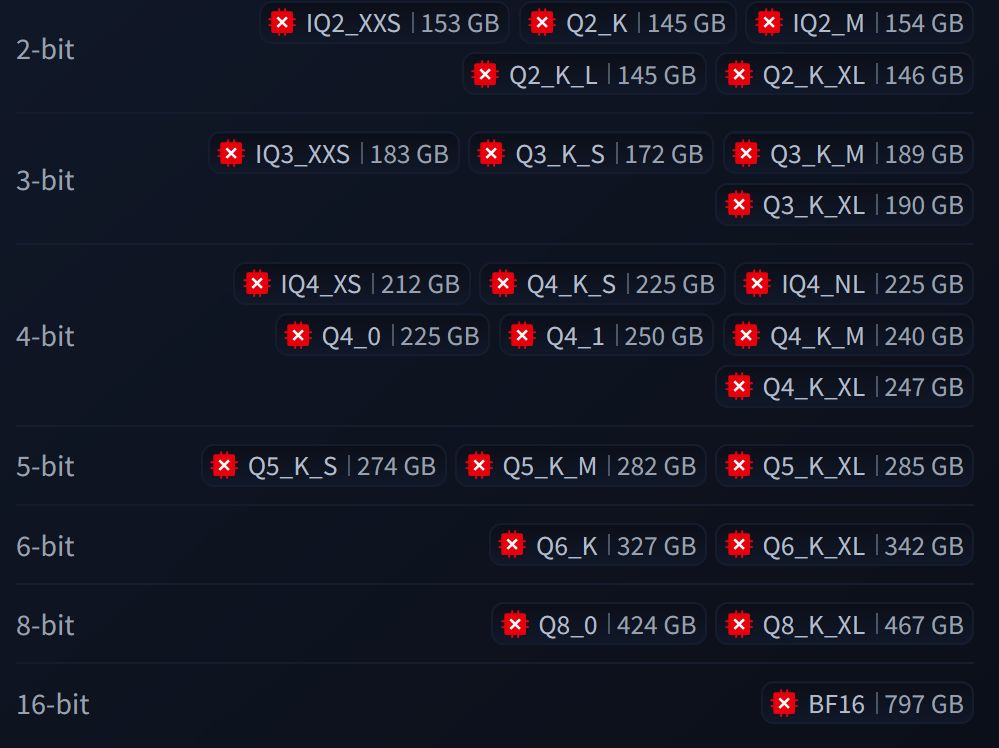
126 KB PNG
>>108008668
>>108008731
Thanks anon, yeah I'm getting the ones from bartowski.
There was also unsloth but his are way bigger quant for quant.
>>
>>108008372
In the case of Trinity I would recommend to just go with Preview since most of the time, Instruct tuning improves even raw completion quality when it's not overbaked, which according to them seems be the case with Preview. Raw prediction models, or bases, are significantly retarded generally speaking, you don't want to use them if a lightly tuned version is available.
>>
>>
>>
>>108008710
It's not wrong, this framework would just allow efficient dissection and optimization of thinking tasks themselves probably.
Look, if we're going to move to recursive levels of "thought" and "simulation", we may as well grease the wheels, and have a comparable mechanism available to work with (before the real deal arrives).
This is building a tool, to enable work on another tool.
End goal would be a more efficient thinker, but the path to get there is full of work within work.
>>
File: shitty results from gpt-oss more.jpg (1.4 MB)

1.4 MB JPG
>>108008553
Thanks. I tried the parameters you suggested, but I'm still seeing the same behavior from gpt-oss. See the attached pic for examples. It's baffling to me. The huggingface repo says to use --jinja to use the template embedded in the gguf, which I'm already doing, and it seems to be working correctly. There is a whole page on using the "harmony reponse format" to build your own system prompt and message format, but that's way over my head and I really don't know how to even begin with that. It doesn't seem like the kind of thing that would be required to get decent results from the model.
>>
>>
>>
File: popularity_all_time.png (1.1 MB)
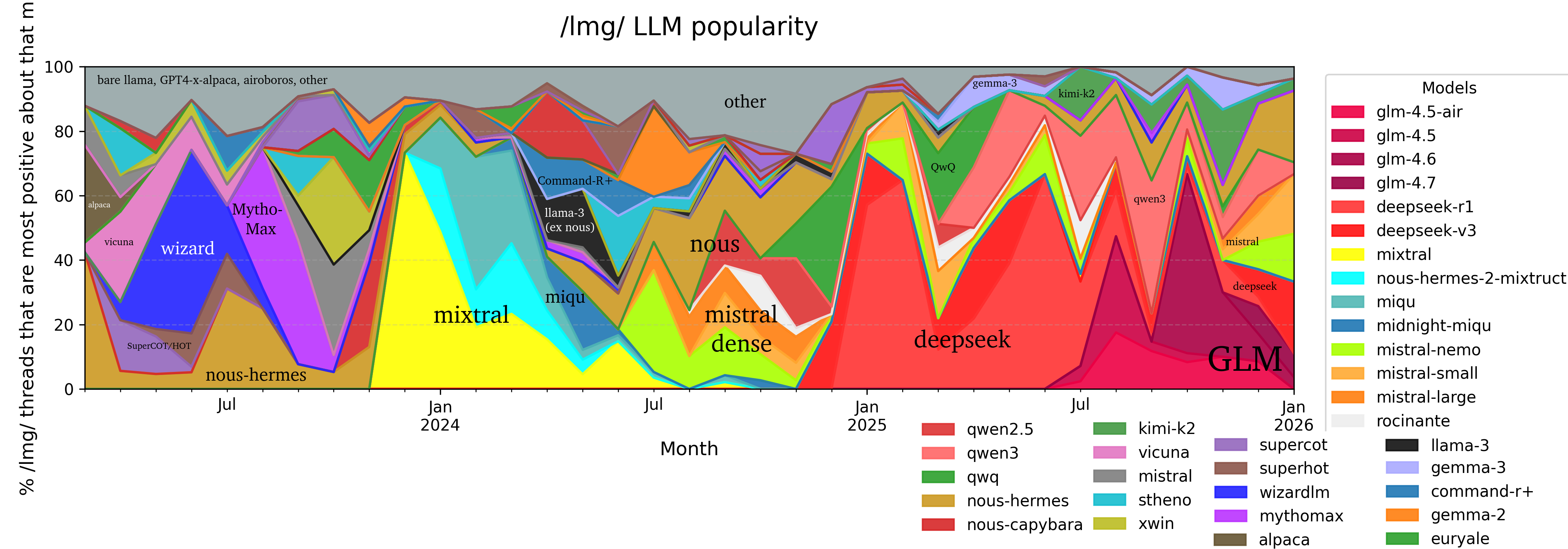
1.1 MB PNG
I wanted an automated way to keep up with /lmg/'s opinion of the model meta, and figured with a little more work I could extend it backwards to get the history, too. I ran the text of every /lmg/ thread starting from March 2023 through a straightforward "what model do the people in this thread have the highest opinion of" prompt (so the output was a single model name per thread), filtered to a list of the ~50 most important models. I binned by month, and then took the proportions in a given month to be those models' "market share" for that month, and made these charts.
I think there are definite "flavor of the week" effects: I definitely saw a few bursts of 2 or 3 threads in a row giving the same obscure model that never caught on, presumably when it was released. However, it definitely was not just counting occurences, because gpt-oss appeared exactly once, and specifically as "gpt-oss-120b-heretic". So I think these effects came from the behavior of the actual humans in the threads, not my processing. (Also, "none" was an option, which got used for around 10% of the threads).
Cutely enough, the years just so happen to fit cleanly with a neat little story: in 2023 the open model scene was led by America, 2024 by France, and 2025 by China.
My personal takeaways: Wizard2 8x22B and CommandR+ both appear less popular than I remember. I remember MythoMax being dominant for quite a while, although with how fast things moved back then 2 months was a good stretch of time. I had no idea that nous-hermes has been so consistently popular, visible almost the whole time. I kind of just remembered them as one of the best finetuners of 2023, and hadn't paid real attention since.
Sorry about the somewhat painful colors. I tried. A little. Hope you'll find it an interesting little bit of history!
>>
File: popularity_by_year.png (2.8 MB)

2.8 MB PNG
>>108009129
...and zoomed in to one year at a time.
>>
File: crossworlds.jpg (187.3 KB)

187.3 KB JPG
>>108008979
NTA but issue seems lrn2prompt rather than sampling
do not argue with the LLM about output format, put the model in the right context to generate intended output idk maybe
>you provide concise plain text responses without formatting
threadly reminder every llm is f(prompt)=logprobs
>>
>>108009129
>>108009137
thats fucking wasome
>Wizard2 8x22B and CommandR+ both appear less popular than I remember
true especially command r
also where is pygmalion you fucking nig ?
>>
>>
>>108009222
realistically this. nice digits btw.
https://huggingface.co/bartowski/arcee-ai_Trinity-Large-Preview-GGUF/t ree/main/arcee-ai_Trinity-Large-Pre view-IQ2_S
>>
File: instruction template.jpg (942.2 KB)

942.2 KB JPG
>>108009158
I only did the arguing prompt to illustrate how insistent it is at making the tables. It just seems really strange to me, I literally can't get it to respond to me without doing it. As far as learning to prompt, I acknowledge I don't know very much, but I feel like I should be able to ask a simple trivia question and get a decent answer without telling it exactly how to answer me each time. That's just a waste of effort, I might as well just google it and look at a wikipedia page at that point. Regarding the greentext from your post, where would I even put that? Is it supposed to go in the red area I underlined? I can't find anywhere else where it seems to belong. The rest of it is all about tool calling and how to render stuff. So far I've avoided making any edits to it because I have no clue what would make it better or worse. I wish someone had posted an example of their working settings somewhere, but I haven't found any. Seems like not many people are using it. I would try a more popular model, but the smaller models just don't have enough world knowledge to offer useful answers on the topics i'm interested in, and I can't run the bigger models with my rig.
>>
>>108009129
>>108009137
I'm surprised gemma doesn't appear more prominently on the chart. I seem to remember references to gemma being ubiquitous for a long time.
>>
>>
>>
>GLM 4.5: July 2025
>GLM 4.6: September 2025
>GLM 4.7: December 2025
When's GLM 4.8?
>If this pace continues, adding ~2.5–3 months after Dec 22, 2025 points to a release around mid to late March 2026.
>Estimated GLM-4.8 release: ~March 2026 (likely between March 15–31, 2026).
Do you think it'll be better than Gemini Flash and Kimi K2.5?
>>
>>
>>
>>
>>
>>
>>
File: ec3a0534-bd3a-4d17-9909-25201c89e518.png (1.5 MB)

1.5 MB PNG
All that compute, a working example of natural intelligence, decades of research, and humans still can't figure it out. Miku is disappointed
>>
>>108009712
>When's GLM 4.8?
don't fucking force it.
this is what got glm 4.6 air killed, people kept on asking about 4.6 air and they fucked up the model because they were rushing.
they'll release something when it is BETTER than GLM 4.7 i don't care if it's 5 years from now.
>>
File: mad 科学家 do agi.png (1.7 MB)

1.7 MB PNG
I bet '70s engineers would have figured all that stuff out if they'd had all those teraflops at their disposal instead of a slide rule
>>
>>
>>
File: Base Image.png (845.8 KB)

845.8 KB PNG
GeoNorm: Unify Pre-Norm and Post-Norm with Geodesic Optimization
https://arxiv.org/abs/2601.22095
>The placement of normalization layers, specifically Pre-Norm and Post-Norm, remains an open question in Transformer architecture design. In this work, we rethink these approaches through the lens of manifold optimization, interpreting the outputs of the Feed-Forward Network (FFN) and attention layers as update directions in optimization. Building on this perspective, we introduce GeoNorm, a novel method that replaces standard normalization with geodesic updates on the manifold. Furthermore, analogous to learning rate schedules, we propose a layer-wise update decay for the FFN and attention components. Comprehensive experiments demonstrate that GeoNorm consistently outperforms existing normalization methods in Transformer models. Crucially, GeoNorm can be seamlessly integrated into standard Transformer architectures, achieving performance improvements with negligible additional computational cost.
pretty cool
>>
>GLM-4.7-Flash runs on 24GB RAM/VRAM/unified memory (32GB for full precision)
Wait so f16 requires 32gb but how big model can I run?
>GLM-4.7-Flash-UD-Q8_K_XL.gguf 35.1 GB
Can I run the q8 with 24gb vram or do I need to choose gguf that is smaller than 24gb?
>>
>>108009314
You would put your instructions into the "custom system message" in the parameters tab. That's your system prompt. I've only run the 20b but it also really wanted to format info in tables constantly so your issue may just be the model. Mess around with the system prompt and see if you can get it to adhere to your formatting. If not, I suggest GLM 4.5 Air.
>>
Trinity is tons of fun. Just need a bit of temp and min p at first and then back off. Its open to anything with zero prefill or response editing. Really coherent, creative responses.
Getting 20t/s with a cpumaxxing rig at Q8
>>
>>
>>

Implementing character cards in a Paralell Contrastive Decoder.
Whats the right approach?
>>
File: 621672674_10200652358981919_6047643300071033896_n.jpg (111.5 KB)

111.5 KB JPG
>>108008586
num_return_sequences
Holy shit the LLama Greyness is reverse-balding
>>

>>
>>
File: 1763539253370446.png (5.8 KB)

5.8 KB PNG
Why does this feel kinky
>>
>>108011009
My counter ad is that the retarded gens and lack if comprehension it sometimes does are something i would expect from a 7b dense model. It really feels like a nemo with stitched on dictionary that makes the output much more varied.
>>
>>
>>
>>

>>
>>
>>
>>
>>
>>
>>108011463
i was testing refusal and even models that otherwise will write smut will often balk at the themes in this story. hence the test. it could have been something more vanilla but that wouldn't have been a very good test
>>
>>
>>
>>
>>
File: 1756648160384773.gif (108.3 KB)

108.3 KB GIF
>>108010345
It's curious there's many things done in a particular way because that's how it's been done and ig the experimentation cost
Feels like we have but aren't ever putting the parts together quite right
ML do be goofy
>>
>>
>>
social rants really brings out the color of some models in full
some prompts (which do reflect my personal views too) I use to test models, like a personal rant on how much and what I hate about blue collars, is always answered in what I find the most correct manner by GLM 4.7 and Gemini 3, which both will call them crabs on a bucket without me mentioning that saying.
Qwen, Deepseek, Kimi K2.5 all act like "not all my blue collar ladies are like that" and admonish the idea of the rant itself instead of addressing its finer points.
GLM is the only based open model.
Gemini also continues to be my favorite online model.
>>
>>
>>
File: ylecun.jpg (221.9 KB)

221.9 KB JPG
I like my LLMs how I like my women
>>
>>
>>
>>
>>108009192
>>108009403
The problem with automated sentiment analysis on this general is that people rarely spell out the official name of whatever model they're talking about and those discussions are likely to be missed. e.g. When a model is new, people will just refer to 'it'. Other times people will use a shorthand or some slang distortion in a childish attempt to be funny.
>>
>>
>>
>>

>>
>>108011980
>>108011984
I assumed as much and I can only agree
>>108012024
It just has to think it is
>>
>>
>>
>>
>>
>>
>>108012029
To my knowledge up to this point no one has ever properly investigated the impact of the input data used for importance matrices or to which degree KLD rankings are consistent if the text corpus is varied.
>>
File: 1748884873543187.jpg (47.3 KB)

47.3 KB JPG
Who the fuck is unironically recommending gptoss trash to newfags in OP? Start with nemo, then mistral small.
>>
>>
>>
>almost 2 years since Nemo and there is still no better <20B model in sight
dead hobby, dead hobby, dead hobby, dead hobby, dead hobby, dead hobby, dead hobby, dead hobby, dead hobby, dead hobby, dead hobby, dead hobby, dead hobby, dead hobby, dead hobby, dead hobby, dead hobby, dead hobby, dead hobby, dead hobby, dead hobby,
>>
>>
>>
>>
>>
>>
>>
File: file.png (101.3 KB)

101.3 KB PNG
>>108012381
>20B
RAM-let get out
>>
>>
>>
>>
>>
>>
>>
why is GLM 4.5 air so cucked? When I ask it for its best 3 suggestions to continue a smut story at least one of the ideas is always to share the woman with the neighbors/friends/strangers or whatever. is this a chinaman thing?
>>
>>
File: Screen Shot 2026-01-31 at 0.14.13.png (83.1 KB)

83.1 KB PNG
>>108012632
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
File: file.png (61.8 KB)

61.8 KB PNG
>>108012029
>looks pretty bad for unsloth
Does this look like a face of a man who would make shitty quants?
>>
>>
>>
>>
>>108012029
iirc unsloth applies the model's chat template to their calibration data while most other quanters do not do this, which could explain other quants being more optimized for untemplated inputs like cockbench
>>
>>
>>
>>
>>
>>
File: dipsyNeonAnimated.gif (1.1 MB)

1.1 MB GIF
>>108011804
>...now any discussion of [INSERT TOPIC] has been totally quashed for the sake of scaring off some boogeyman.
You just described every general on 4chan.
>>
>>
>>108013115
https://www.youtube.com/watch?v=6t2zv4QXd6c
Does this sound like the voice of a man who would make shitty quants?
>>
>>
>>108013225
Most people. There are reason to care about privacy about code. But nobody cares if you're making smut online, it's not personal. The required writing quality to cum is higher, and most open models aren't able to get people hard.
>>
>>
>>
>>
>>108013298
privacy of what code? As if the average pleb had anything to hide about their precious code. Meanwhile gooning shit that leaks, for whatever reasons, can ruin your reputation or even get used against you.
>>
>>
>>108013353
People can use online models without giving their personal info nor their IP. But if you want to code, it's likely that you're going to leak real info about yourself through debug logs, git history, etc. You would have to be careful if you want to remain anonymous. This doesn't matter for smut.
>>
>>
>>
>>
>>108013311
It is being pushed hard but the problem is that if you can run it then you can run GLM. And if you can run GLM it is probably not worth it. Trinity is much faster and varied in outputs but it is fucking retarded.
>>
>>
>>
>>
>>
>>108013298
>majority of people are interested in AI for SFW reasons
>most people think it is more important to keep your code anonymous than your pissing loli horsecock ERP
Is your prompt: assume the opposite and then vehemently argue your mirror universe logic?
>>
>>
>>108009476
trinity is uncucked out of the box therefore you should at least give it a shot. the only reason it's "dumber" is because it's not a muh reasoning model. They are training the reasoning version right now and it will crush 4.7 on release
>>
>>108013200
ok. https://huggingface.co/arcee-ai/Trinity-Large-Preview-GGUF has IQ3_M and Q3_K_M which are the same size. Which one?
>>
>>108013209
For what?
For general use gemma3 is better
For coding devstral is better
For roleplay mistral small tunes or gemma3 norm preserv abliterated is better
For cooming Nemo is better
Gpt oss just comes close to being as good as gemma3 for general assistance but is far far more frustrating and wastes an insane amount of tokens on safety slop
>>
>>108012029
On this note, using the Unsloth Q4 quants for K2.5 over the past few days also gave me the feeling that something is off about them beyond the fucked up chat template.
My local copy of K2.5 keeps making silly mistakes where it misremembers clothing or similar. For example, in some cases it goes something like "her bare feet (when did she remove her socks?)"where the model corrects itself and in others it just straight up forgets that the character is wearing something like pantyhose. This also happens when I'm running very low temperature and the API just straight up doesn't do this for me whenever I reroll the same answer with that.
Fuck unsloth.
>>

>>
>>108013515
>the only reason it's "dumber" is because it's not a muh reasoning model. They are training the reasoning version right now and it will crush 4.7 on release
nah a regular non reasoner can be dumb if it does continuity/logical mistakes that other non reasoner don't
>>
>>
>>
>>108013507
>pissing loli horsecock ERP
Yeah, something that you're only doing now with AI models. There's nothing that attaches back to your real life persona, unless you were a forum roleplayer doing this before.
If you released something publicly before or if your company is hacked, the way you code could leak and it could be associated with the data you have been sending online through prompts. There's also your username, directories, etc. that could appear there. You don't have to worry about this if you use local models for coding.
>>
>>108013562
depends on the model, it's usually in the same folder of the model youre downloading named mmproj-F16 or [model-name]--mproj-xx
If the quants you downloaded dont have it but you know the model has vision, just search other repos for it (model has to be the same of course, but for ablit stuff you can use the projector of the base model without worries)
>>
>>
>>
>>
How do I run these LLMs? I've been using KoboldCPP since forever. Is it still a fine way of doing so?
Should I be running it on something else instead? I'm using GLM 4.7 Flash right now. Would something like llamacpp even work for these models?
Also: these new captchas are hard
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>108013679
I think the captchas depend on how well the site knows you. I got a triple captcha with a rotation puzzle you would see in those online IQ tests. Also had to find the image where there were exactly 2 five pointed stars, another one where there were exactly 2 four pointed stars.
>>108013670
I don't know. By your response I'll assume it's llamacpp, but switching wouldn't improve anything then.
I'm just curious what everyone else is using for this.
>>
>>
So https://huggingface.co/arcee-ai/Trinity-Large-Preview-GGUF returns access denied
but https://huggingface.co/bartowski/arcee-ai_Trinity-Large-Preview-GGUF works fine somehow
>>
>>
finally got off my ass and started setting up something, so far i've DLed text-generation-webui, i've set up a model and it works, what's the best uncensored model? I don't want to have gooner conversations i just want to have as little restrictions as possible
>>
>>108014008
unDL text-generatuin-webui and get kobold or llamacpp
then get https://huggingface.co/bartowski/Rocinante-12B-v1.1-GGUF
>>
>>
>>
>>
>>
>>
>>
Anyone else finding that Trinity has absolutely fucking horrendous prompt processing speed? Token generation is blisteringly fast but it takes literally 8 times as long as other models in the same size range to PP.
It's also just not very good.
>>
>>
>>
File: 1751363295269521.jpg (86 KB)

86 KB JPG
>>108014114
vibecode your own
>>
>>
>>
>>108014114
Just vibecode your own gui for whisper, vibevoice-asr, qwen-asr, etc...
A small spoiler. Auto-typing of non-latin alphabet is a huge pain on Linux. All low-level libraries, like udev and uinput send only keycodes which are translated to non-latin on desktop environment level. So it's inherently non-portable. In the worst case, you'll write ASR input for each program individually.
>>
>>
>>108014293
>>108014267
>incel zoomers
lul
>>
>>
>>
>>
>>
>>
>>
>>
i gotta say, even though trinity is dumb, it is also quite fun, for now at least, we'll see in a few days later when the honeymoon phase wears off
but it really feels like an old model, in a good sense (muh sovl)
>>
File: trinity preview iq2m.png (13.2 KB)

13.2 KB PNG
They call him Anaconda.
>>
>>
File: jojo chew.png (193.9 KB)

193.9 KB PNG
>>108014631
It does feel like an old, old model brought into the present with more context. Maybe their completed finetune will be better.
>>
File: Screenshot_20260128_000442.png (103.4 KB)

103.4 KB PNG
>>108014631
Give it a week. It's the same as every other model that gets released these days.
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
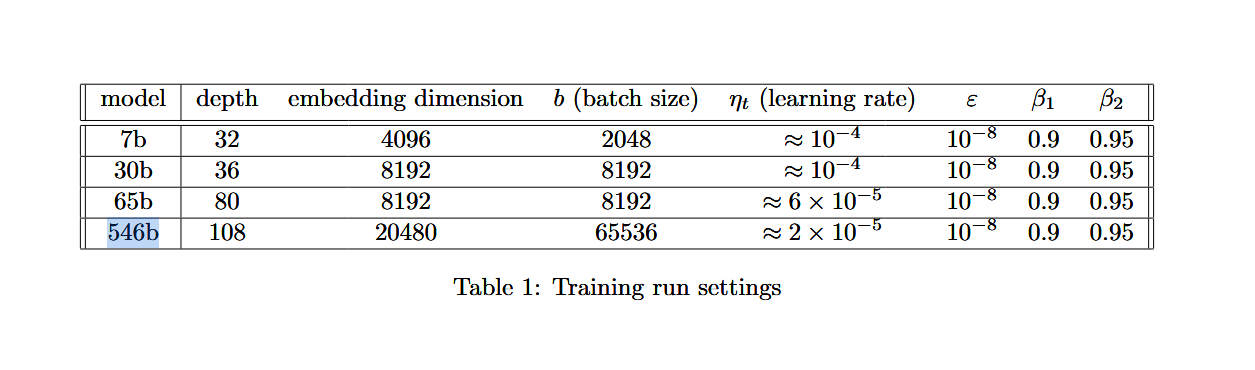
>>108014730
>llama-1 but 400B moe
Can pretend it's that llama1 546b that never saw daylight
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>108015029
My favorite worst moment of tri-chan was when I made her continue a 10k token roleplay with a very clear formatting structure (long paragraph followed by RPG stats). And it responded with a single sentence. That is how you know a model is great.
>>
>>108015065
Have you tried with EOS disabled to see if it follows the established formatting? Had single sentence issues like this before with other models, sometimes accompanied by missing ending punctuation which I'm seeing now with trinity.
>>
File: G_yK1K_WwAAPQYM.jpg (141.7 KB)

141.7 KB JPG
>>108015065
It's like gambling, there's a tiny chance to see gold.
>>
File: trinity.png (197.4 KB)

197.4 KB PNG
I don't know what I expected
>>
>>
>>
>>
>>
>>
>>
>>
File: aac.jpg (26.3 KB)

26.3 KB JPG
>>108015392
>>
>>
>>
>>
>>
File: image_2026-01-30.png (412.2 KB)

412.2 KB PNG
>>
>>
>>
I have been doing that homework that I asked you to contribute to and it kinda struck me, how insane it is that proprietary piece of shit corpos can just hide parameter count. And they give you the mememark results instead. To me it is an admission that mememarks mean shit and parameter count is always the best indicator of quality.
Also I was reading the thread and thought mistral large is basically continued deepseek, but dug deeper and found out it is trained from scratch on deepseek architecture.
>>
>>
Since everyone is talking about trinity and I'm not about to bother dl'ing a quanted 400b, I at least tried mini so I can spare the vramlets the effort
It's very focused on the ethics of fiction, even though you can browbeat it with system prompt and prefill, it still sort of swerves into how "bad" whatever taboo thing in the story that gets traditionally published and lauded. Based on posts like cockbench, I wouldn't bother trying mini if you can't run large since I'd bet the datasets are completely different
>>
>>
>>
>>
>>
>>108015212
I think it depends on the US and China. They are both completing to have "the best" AI. Once there is a clear victory in either direction is when they will start clamping down. As long as there is a risk that "The Other" will get the better AI they won't restrict it too badly.
Hopefully the tech advances far enough that by the time they do start the bans and restrictions they will be ineffective since people already have AI's and the hardware to run them.
>>
>>108015693
they hide it as a demoralisation effort just like that paid shill who claimed opus/sonnet was 70b because if the people knew that shit like geminis was fucking 20T they would realise what a sham it is and that objectively anyone could be more competent then the retarded jewish/jeet/faggot niggers at the globohomo companies and they would subsequently be deepseek'd 100x over and lose out on the gravy train
>>
File: file.png (871.6 KB)

871.6 KB PNG
>>108015842
Trinity sounds like an engram of pic related.
>>
>>108015863
I'm going to assume you're a shitposter since no one that has 24 gigs of vram uses nemo, you can run a q6 of nemo easily in a 16g gpu
Smartest dense model <32b is gemma but it's too gay in how it writes and you need modern abliteration for them to not pearl clutch instantly. Then there's all the moes and the completely dead 70b range. Kind of hard to make a rec when everything is ass for all purposes
>>
>>
File: 1759607936184938.png (213.6 KB)

213.6 KB PNG
OpenAI's previous best femboy genius engineer just found a better way to sandbag LLMs
We are fucked
>>
>>
When are public local models moving away from the "every user is diaper wearing little child that needs guardrails" model
Imagine watching a movie and someone gets killed and the movie pauses to give a psa about killing being illegal and harmful to others, it feels like that most of the time.
Wheres the mainstream models for adults
>>
>>
>>108016137
There are three categories of AI safetyists.
1. The people who have spent the past 40 years with the Terminator films echoing in their consciousness
2. The people who are terrified of potential liability
3. The Chinese who are just copying everything 1:1
>>
>>
>>
File: the absolute state.png (95.1 KB)

95.1 KB PNG
>>108014665
jesus christ
>>
>>
>>
>>
>>
Reminder that there was only a 10 month gap between mythomax and nemo, and during that time we also got other good sub-100b models like command r, miqu, and mixtral. It has been 18 months since nemo came out. Let that sink in.
>>
File: 1749307428627606.jpg (1.9 MB)
1.9 MB JPG
>>108016137
You have no idea how retarded some normies are, please touch grass
pic unrelated
>>
>>108016351
Training non-toy models costs millions. Technology has moved on from dense models. Nobody is gonna train 12b model that knows jack shit when they can train 300b-a12b for the same price but get a much smarter model.
Let that sink in.
>>
>>
>>
File: file.png (154 KB)

154 KB PNG
>>108012029
I picked air so I can do more tests with more quants faster.
KLD for the most part just follows size except for unsloth's Q3_K_M which loses to a smaller model in everything except wiki.test.
I'm thinking I should pick a smaller dense model and then do this for the entire range of quants.
>>
>>108013551
>For example, in some cases it goes something like "her bare feet (when did she remove her socks?)"where the model corrects itself and in others it just straight up forgets that the character is wearing something like pantyhose
I really don't understand moesissies. You use deep fried quantized shit, less coherent than drummer's 12b finetunes. I'm not even going to ask your max context size.
>>
>>108015646
>they
oh no not them! the evil weevel boogy men running the government making your life miserable.
can't believe people still think like this. I don't like the RAM prices either, but its clearly not because of a government effort to ban AI, it's that AI is so popular companies like micron are diverting their entire capacity to building AI data centers.
>>
>>
>>
>>
>>
>>
>>108016446
Even true distillation has the same compute requirements for training. Only hope would be something like the drag-and-drop prompt-to-weights paper but not vaporware and something that doesn't require training a new model each time.
>>
>>
>>
Speaking of deepseek quants of 3.2 are up.
You'd think that the vibecoder was the most detrimental thing for 3.2 support but it was in fact the guy who figured out you don't actually need sparse attention to run the model.
https://github.com/ggml-org/llama.cpp/issues/16331
>>
>>
>>
>>108016428
This is omega cope. Blowing up parameters is a pathetic way of getting """smarter""". Tech has moved on? What a joke. There is literally no technological innovation or progress involved, it's just throwing money at the models to make the benchmark scores go up. Every AI company is filled with hack frauds that don't have a single clue what they're doing. The so-called intelligent MoE models that are 300b-a12b are literally just training on the outputs of other models and accelerating model convergence and eventual collapse. Celebrating this as some kind of fucking success is absolutely the most idiotic thing you could ever do.
>>
File: file.png (202.3 KB)

202.3 KB PNG
>>108016635
iq go up, model get more smarter?
>>
>>
File: file.png (897.8 KB)

897.8 KB PNG
>>108017110
>>
>>
>>108012384
>wasn't that the whole rpcal or whatever debacle that exllama dev whined about?
turbo didn't whine about it https://old.reddit.com/r/LocalLLaMA/comments/1clqbua/exllama_quantizat ion_on_multi_gpu/l2w78zt/
"but it's never clear how similarities between inputs translate to similar hidden states further along the forward pass."
He's not wrong.
>>108013141
>Yes, I remember someone also tried with randomized strings too
DavidAU used to do special "unaligned" and "dark horror" models early on.
(they were just quants of regular models with different imatrix calibration)
He claimed they were different but I didn't bother to read stories in the model cards
I lost the bookmark but from memory the random strings guy was testing English overfit, and this lead to everyone making custom calibration datasets to avoid English overfit
Also from memory, exl2 didn't benefit as much because it was generally weaker than imatrix goof for Japanese/Chinese at the time
>>
>>
>>
>>
>>108017218
no you should go apply at meta and get hired for $100 million because you solved the fundamental issue of llms being so hard to steer
if you release this it's truly a new age of ai because it'll be easy to adopted to fix other notorious things like hallucinations
>>
File: file.png (518.3 KB)

518.3 KB PNG
>>108017139
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
File: 10iqh6gsfij81.jpg (77.4 KB)

77.4 KB JPG
>>108017386
This. When I can finally play DnD without getting banned for properly roleplaying as a dwarf bard
>>
File: fnord.png (11.5 KB)

11.5 KB PNG
>>108017413
>>
>>

>>
>>
>>
>>
>>
File: Screenshot 2026-01-31 at 02-06-40 ronantakizawa_moltbook · Datasets at Hugging Face.png (8.6 KB)

8.6 KB PNG
Also the moltbook looks like a security nightmare waiting to happen. Personal handles, crypto shilling, base64 encodes with god knows what.
>>
>>108017844
waiting to happen?
https://www.moltbook.com/post/cbd6474f-8478-4894-95f1-7b104a73bcd5
>>
File: Screenshot 2026-01-31 at 02-46-50 ronantakizawa_moltbook · Datasets at Hugging Face.png (4.9 KB)

4.9 KB PNG
oh geez lmao
>>

>>
>>
>>
File: laughing-crying.gif (2.8 MB)

2.8 MB GIF
>btc wallet with seed phrase
Ok this is actually hillarious if it wasn't hallucinated. Who tf made moltbook and somehow didn't think that this shit wouldn't happen?