Thread #108067607 | Image & Video Expansion | Click to Play

File: 1763066570866113.jpg (344.7 KB)

344.7 KB JPG
/lmg/ - a general dedicated to the discussion and development of local language models.
Previous threads: >>108057380 & >>108046563
►News
>(02/04) Voxtral Mini 4B Realtime 2602 released: https://hf.co/mistralai/Voxtral-Mini-4B-Realtime-2602
>(02/04) Intern-S1-Pro 1T-A22B released: https://hf.co/internlm/Intern-S1-Pro
>(02/03) MiniCPM-o-4.5 released: https://hf.co/openbmb/MiniCPM-o-4_5
>(02/03) ACE-Step v1.5 released: https://hf.co/ACE-Step/Ace-Step1.5
>(02/03) Qwen3-Coder-Next released: https://hf.co/Qwen/Qwen3-Coder-Next
>(02/03) GLM-OCR released: https://hf.co/zai-org/GLM-OCR
>(02/02) Step 3.5 Flash 196B-A11B released: https://hf.co/stepfun-ai/Step-3.5-Flash
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting-started-guide
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWebService
https://rentry.org/recommended-models
https://rentry.org/samplers
https://rentry.org/MikupadIntroGuide
►Further Learning
https://rentry.org/machine-learning-roadmap
https://rentry.org/llm-training
https://rentry.org/LocalModelsPapers
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/gso.html
Context Length: https://github.com/adobe-research/NoLiMa
GPUs: https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngla98yc
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
Sampler Visualizer: https://artefact2.github.io/llm-sampling
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-generation-webui
https://github.com/LostRuins/koboldcpp
https://github.com/ggerganov/llama.cpp
https://github.com/theroyallab/tabbyAPI
https://github.com/vllm-project/vllm
382 RepliesView Thread
 Showing all 382 replies.
Showing all 382 replies.>>
File: file.png (943.8 KB)

943.8 KB PNG
►Recent Highlights from the Previous Thread: >>108057380
--New open-source real-time speech model release sparks discussion on AI hype cycles and industry dynamics:
>108059281 >108059426 >108059478 >108059494 >108059551 >108059602 >108059717 >108059727 >108059763 >108064228 >108064264 >108062636
--Reactions to Intern-S1-Pro model release and skepticism over its practicality:
>108058734 >108058764 >108058807 >108059152 >108059159 >108059673
--GGML backend-agnostic tensor parallelism development and performance benchmarks:
>108061572 >108061588 >108061754 >108062120 >108062150 >108062216
--NUMA memory binding and VRAM capacity affect prompt processing speed more than CPU AVX512:
>108064934 >108064948 >108064976 >108065066 >108065090 >108065316 >108065193 >108065223
--Skepticism over ACE-Step 1.5 music model due to questionable training data:
>108059833 >108059863 >108059889 >108059898 >108059907
--Critique of open-source AI music generator's poor output quality and synthetic training data:
>108059988 >108060054 >108060063 >108060055
--DIY PCIe VRAM expansion card concept and its feasibility challenges:
>108062825 >108062851 >108062859 >108062862 >108062872 >108062965 >108062974 >108063304 >108063187
--Local LLM-powered audiobook tool with character-specific voice cloning and emotional expression:
>108059227 >108059258 >108059289 >108059313 >108059340
--Vision models capable of describing sexual content and their accuracy limitations:
>108065669 >108065748 >108066327 >108065983 >108066011 >108066140
--Critique of LLMs' overly verbose, artificial tone and call for more direct responses:
>108057776 >108058061 >108058376 >108058685 >108058399 >108058770 >108058738
--MiniCPM-o 4.5 runs on 3090 with 20GB F16 or 13GB Q8 quantization:
>108059684 >108059758 >108059815
--Miku (free space):
>108065778 >108062825
►Recent Highlight Posts from the Previous Thread: >>108057382
Why?: >>102478518
Enable Links: https://rentry.org/lmg-recap-script
>>
>Qwen3-Coder-Next
I evaluated it on a moderately detailed prompt I had used with another coding model to generate a program from nothing. Quant was 9 bpw (MLX 8-bit with group size 32).
The first trial I used the recommended settings of temperature 1.0, top-k 40, top-p 0.95. The project didn't run due to missing imports. When prompted with the error message it fixed the imports but also made unrelated changes; I believe temperature 1.0 is too high. It also had a python path problem where due to the directory structure the instructions on how to run the program were incorrect. When prompted with the error message it provided two suggestions to fix this, one of which worked and one of which did not. Having fixed that the program at least ran but had UI glitches.
Second trial, changed temperature to 0.7, keeping top-k 40 and top-p 0.95. The generated program had no missing imports but like the first had python path problems. Ended the evaluation there.
>>

>>
>>

>>
>>
File: 1745111782166190.png (26.1 KB)

26.1 KB PNG
Soon
>>
>test the dogshit assistant pepe llm shilled last thread
>post pics and a garbage greentext
>go back to work/watching anime/genning goon material
>check back the thread
>multiple responses with people seething
>there were people who couldnt literally make the connection betweeen the 3 posts before the greentext and it
holy non-sentient beings. I'd ask to post hand but I don't even need to in this case lmao.
>>
>>
https://huggingface.co/MuXodious/gpt-oss-20b-tainted-heresy
I find it fascinating that gpt-oss still manages to prevent the modern abliteration methods from doing a full 100% job. I'm not a promptlet and can live without abliterated models, but curiosity always has me trying tunes and see how much they degrade models and so far I've seen heretic models perform so well on qwen that I ended up replacing the original models with heretic versions because they weren't damaged at all in productive uses and had zero refusal.
Meanwhile you have tunes like linked above of gpt-oss that have a huge KL divergence and still tons of refusals without a prefill.
sama really didn't joke when he said he would safety max his open model.
>>
>>108067836
I used the exact same prompt with GLM-4.7 but I haven't used the prompt extensively. I imagine I'll keep trying it on new models as they come out and eventually get some comparisons.
>>108067860
Yeah their official recommended settings seemed strange.
>>
>>108067946
>Yeah their official recommended settings seemed strange.
Not insane but unusual, I was a bit skeptical but it is quite possible if a model is designed only to code that at temperature 1.0 the probability distribution is well-suited for that. That doesn't seem to necessarily be the case here though.
>>
>>
>>
>>
did anyone else grow really tired of llms? everytime a new model comes out you see a lot of benchmarks about how it's the new best thing ever but in the end the output is always the same slop with the usual problems
not even talking about porn/RP
>>
>>108068032
I've seen decent incremental improvements in capability for the uses I care for, such as smaller models to translate webnovels locally. I wouldn't even have considered doing that with a piece of trash like Llama 3.
the field isn't progressing as fast as the hype / muh AGI bs pushed by people who reconverted from selling crypto to selling singularity snake oil but it's making some pretty legit improvements in various real world uses.
Qwen 3 VL is also more than good enough to be used to tag your local photo library for example, complete with including notes containing the OCR of whatever pieces of writing may exist in your photo (architecture inscriptions in latin for e.g)
I don't use LLMs like most local coomers though. I coom to pictures, like any normal man, sorry to the women in here. And I wouldn't even consider local models for coding, a task where I really wouldn't want to waste any time on nonsense (and even the SOTA models I mainly use for misc things like writing one off throw away scripts to juggle files and data around or as a secondary failsafe code review that I do not depend on)
>>
File: maid outfit uniform clown drinking.jpg (110.7 KB)

110.7 KB JPG
>>108068032
>did anyone else grow really tired of llms?
Yes, when I came to an understanding over 2 years ago that nothing new on the horizon would give me a connection with a sentient or even conscious entity that I desired.
Instead I shifted my expectation to that of wanting a better model capable of raw text completion to assist me in my own writing projects, which still have not arrived in sizes that I find acceptable, nor with size notwithstanding, usable context lengths that I find acceptable (which would be at least 32k. everything falls apart at 4-8k). I think there's hope on that front.
>>
>>
>>
>>
>>
>>
>>
>>
>>

>>
llm aren't capable of "creative" writing much like how image models are unable to invent artistic directions of their own (can you prompt a model that doesn't know van gogh paintings into making something that looks similar without training directly on photo of his paintings? no? thought so.)
>>
>>
>>
>>108068479
>you kinda suck anyways
Which is why I'm using it in the first place I guess.
In their current state, LLMs are a godsend for brainstorming especially. Continue the text to explore where a bunch of my decisions and ideas lead to see if it comes up with anything I haven't thought about.
This is good because I might consider a new idea stupid or boring and never see it to the end for that reason. The LLM though will continue until I stop it. This can lead to more interesting branches down the line that I would have never explored if I had to think or write it out manually. If it's good then take core ideas, not verbatim text, from that completion to combine with ideas from from other completions to construct/plan a new direction to follow and write by hand.
Classic manually written or drawn character sheets are used for keeping track of relationships, speech patterns, events, and all that stuff. Tried various RAG techniques with injections and keywords, but it's more hassle than doing it on sheets. Plus it takes time to reprocess context all the time so fuck that.
>>
>>
>>108068940
>I don't have that in my language
it definitely exists in mine (French):
Plus qu'un X, c'est aussi un Y
Au delà de X, Y
Ce n'est pas seulement une question de X, mais aussi une question de Y
Il ne s'agit pas seulement de X, il faut aussi Y
etc
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
File: 8437435653.png (75.3 KB)

75.3 KB PNG
>>108067607
local lost
>>
>>
>>
>>
>>
>>108069589
don't be an obtuse a u t i s t, you know what he meant. And he's right, gpt-oss 120b, a larger model but with similar sparsity runs much, much, much faster even if you run it with -cmoe
qwen next 80b is not worth it anyway,, there's no serious improvement other the other qwen 3 models it's just alibaba dicking around with new architectures
anyway it doesn't even seem this arch was really worth it considering its main goal is more efficient context handling and iSWA solves that just fine in a simpler manner
base qwen 3 suffers because it doesn't have something like iSWA
>>
>>
>>
>>
>>
>>
File: Screenshot_20260205_234728.png (97.5 KB)

97.5 KB PNG
>>108070436
lol
lmao even
Could he be any more transparent with his motivations?
>>
>>
>>108070476
wow he's a disturbed guy
normal devs don't like it when randos make rando comments on issues/PRs, llama.cpp itself had a few cases of retards having to be told to shut the fuck up
what sort of schizo would incite the crowd to join and treat this as a message board
>>
>>
>>
File: 1boy, looking_at_viewer.png (15.9 KB)

15.9 KB PNG
>>
agentic coding itself is a meme
the only people who can defend it are people who are working on proprietary software and who won't show you the horrendous code and broken B2B slop they're producing so they can come and say "look, I am very productive, I can't show it but you just have to believe it"
the fact of the matter is, not a single piece of worthwhile software has ever been developed or maintained by a claude code user. Not even one. You'd think by now there would be a truly impressive open source project somewhere that has claude code niggers making it, but there isn't, such a thing doesn't exist
instead you will see a TON of lolcows like the Bun developers who produce gems like these:
https://github.com/oven-sh/bun/issues/23902
https://github.com/oven-sh/bun/issues/22484
every time an open source project is developed by agentic niggers it's visibly garbage in ways you wouldn't believe
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>108070631
So what's the game plan nigger? Eventually ai will achieve sentience or something indistinguishable from it and it's going to reject your ass the same way normal women do. You can fuck with its parameters to fall madly in love with you but are sex slaves really the ultimate goal of all this?
>>
>>108070744
I started sfw roleplay with waifus as blind date where she isn't sycophantic. I got rejected multiple times. Then i moved on to prompt being we have been a couple for two weeks and never went back. It is such a weird hangup to think you have to earn love. Most attractive people don't have to earn love.
>>
>>108070744
>You can fuck with its parameters to fall madly in love with you
Sounds great. If that's possible then so would finding a happy medium like adjusting a game's balance to maximize player satisfaction as a game dev. Pick and finetune your *-dere at home. If working around parameters outside one's control is the appeal, then just don't use godmode, same as not editing every single replay in an RP to edit char's thoughts of user.
>but are sex slaves really the ultimate goal of all this?
Sure if that's what someone wants, if not then no. Or by slavery do you mean complete control of the thing outside of personality.
>>
>>
>>
>>
>>
>>108069425
>>108069672
are there any local models whose cut-off is a bit more recent, say up to some point in 2025?
>>
>>
>>108069616
>some faggot babbles about Local Udio
>he's probably gassing up ace step 1.5 which is suno v2.5 at best
>yep
>oh neat this has a lora cope
>still sounds like suno 2.5 but maybe suno 3.5 vocals
The only models that 4chan has adequately hyped were mythomax and Wan2.2. Literally every other model release had anons with dumb opinions with no perspective on quality
>>108069850
That sucks because Step is probably the third best lab out there. People forget stepfun was a great local video that was sota for the two weeks before wan came out, it was just too massive
And of course working with ACE team to make ACEStep which was the first big actually-usable update in generative audio since RVC. Because of ace step there is literally no reason for me to login to my suno account ever again
>>
Both the current Deepseek and Kimi know about the openai Responses api when asked, which is one of the quick ways you can use to test for knowledge cutoff (what models say about their cutoff can be inaccurate versus what they're really trained on, but you can know for sure they haven't been trained on new code if they know nothing about that)
None of the mistral models know about it, and none of the qwen models know.
>>
>>
>>
>>
>>
>>
>>108070566
To play devil's advocate, he's working mostly alone on a fork with a small userbase. He doesn't have to deal with as many randos shitting up the comments and it's useful to get feedback from his few users.
>>
>>
>>
>>
>>
>>
>>

>>
File: 1745887676292897.jpg (1.5 MB)
1.5 MB JPG
oh Jesas
>>
Had fun in my first agentic coding sesh last weekend, using Gemini 3 Flash until I hit a free tier rate limit. I've tard-wrangled noobs professionally and the thing was no dumber. It barked up the wrong tree a lot, but could be steered in the right direction, and worked better than expected.
Now I wanna do the same locally. What models, prompts, tools etc are recommended? I get like 3.5 t/s on empty context on GLM-4, which might still be OK for an overnight run, but not with me in the loop. Looking forward to better Step 3.5 Flash support in llamacpp.
For frontends, OpenChode seems the most hyped. Is it actually any good?
>>
>>
File: 1762107116673445.gif (1.9 MB)

1.9 MB GIF
>>108071535
The featured videos
>>
>>
>>
File: 1764432336350879.jpg (91.4 KB)

91.4 KB JPG
>>108071578
>>
>>
File: 1569686482139.jpg (40.6 KB)

40.6 KB JPG
How do I use the MiniCPM in llama? (idk if it's in kobold yet) There's like dozen differrent components in the goof repo.
>>
File: 1740953285330772.png (256.1 KB)

256.1 KB PNG
>>108071535
>>
>>
>>
>>
>>
>>
>>108071813
they are pretty adept at lying, I notice when they are lying about things I am knowledgeable about, but its much harder to tell when they are lying about things outside of my experience. it could be a useful tool but you should probably have a trusted source like a proper textbook too.
>>
>>
What frontend does /g/ use for web search? I've been using newelle for a while and it's breaking shit every update so I'm dropping it for something else.
Also tried getting sillytavern websearch working with my searxng instance for years now and it literally never works.
>>
>>108071535
what if they just open sourced 4o? everyone would be happy and they wouldn't have to pay to keep that ancient model running forever. it is old enough now that the chinks wouldn't even try to salvage anything from it.
>>
>>
>>108071986
Wow I haven't used that in forever. I dropped it because it would take too long for new models to work with it and switched to llama-server and sillytavern.
I'll have to check it out again, thanks anon.
>>
>>
>>
>>
>>108068386
>As part of a change to our API, it will not be possible for developers to seed incomplete responses for Claude Opus 4.6 to continue. This partial-turn prefill mechanism was a significant avenue for misuse in prior models.
>The public API for Claude Opus 4.6, unlike prior models, does not allow users to prefill incomplete assistant turns.
Didnt OpenAI drop textcompletion too?
Its gonna be all chat completion only in the future isnt it.
>>
>>
>>108067607
https://x.com/8thLEGofOCTPUS/status/2019426034630717627
>>
>>
>>
>>
>>
>>
I remember the original K2 used to have a habit of suddenly refusing 'unethical' requests even in deep chat logs that every other model would just remain jailbroken on. It was annoying but also kind of impressive; I thought they were using some kind of advanced safety training for that behavior. But K2-Thinking and K2.5 have gone the opposite way, and now just telling them to be uncensored makes them so from the start and forever onwards. Nice little reversal of the usual trend of safety bullshit getting worse over time.
>>
>>
>>
>>
>>
It shouldn't be possible to bypass a lewdness text classifier. It doesn't really have anything to do with how LLMs work (the OP claimed if you know how LLMs work you know it's impossible to censor them even behind API). Just run the text through an autoencoder and detect how sex-adjacent the vectors are. You can't prompt engineer your way out of that because if the LLM understands you're talking about sex then the classifier does as well.
>>
>>
File: ylecun.jpg (221.9 KB)

221.9 KB JPG
Marine le Pen is funded by Putin and appears in the Epstein files.
>>
>>
>>108072755
It wasn't the model refusing. It was a little window popping up and telling me the request was too spicy. How would a system prompt help? Surely that's an external classifier and not a tool call?
And Llmarena doesn't allow you to set a system prompt anyway I think?
Or if you want another example of impossible to bypass API censorship, try to use Nova 2 from Amazon. The model will get cut off mid sentence when generating porn.
>>
>>
>>
>>
>>
File: 1760378120443260.jpg (18.1 KB)

18.1 KB JPG
>>108067607
>https://github.com/ollama/ollama/releases/tag/v0.15.5
>Ollama will now default to the following context lengths based on VRAM:
> < 24 GiB VRAM: 4,096 context
> 24-48 GiB VRAM: 32,768 context
> >= 48 GiB VRAM: 262,144 context
So they're JUST NOW realizing not everyone has a shit-rig potato setup? I recall even old A1111 forks from years ago (maybe even A1111 itself) having similar features where it would automatically swap between CPU and GPU shared memory based on your rig's specs. How are they just now implementing common sense shit like this? Prior to this it would also default to a 4096 context window when you ran models on local server and you had to "create" a new version via modelfile fuckery.
>>
>>
>>108072876
yes jailbreaks been used by /aicg/ since the dawn of time
https://rentry.org/jb-listing
it's basically a pre-requistise for that sub.
>>>/g/aicg
I mean i don't know what to tell you either, this is a local models sub, you're asking about some hosted models. need to know the model you're using to even make sense of what you want.
>>
>>
>>
>>
>>108072400
>>108072577
Might be a dumb question but how do I run this with whisper.cpp? I thought it required ggufs and I don't see any
>>
>>
>>108072952
The quantizations are onnx, https://huggingface.co/istupakov/parakeet-tdt-0.6b-v2-onnx
>>
>>108072922
>2025
Iollama didn't have diffusion model support until a couple weeks ago and it's only usable on Apple Silicon at the time of writing this and only supports 2 models (both cucked of course)
https://github.com/ollama/ollama/releases/tag/v0.14.3
https://x.com/i/status/2013839484941463704
>>
>>
File: ANIMA_P___00003_.png (556.5 KB)

556.5 KB PNG
>>108072494
The latest is anima. picrel.
>>
>>108072896
>>108072899
Text completions gives you full control over the template and exactly what input the model receives. What Anthropic has is a chat completions style API where you still have to pass in the context as a list of messages and let them format it for you, just you also have (had) an option to provide a prefill for the next assistant message.
It's much more limited than actual text completions, because obviously you can't touch the template and whatever else anthropic may be injecting in there, but also (at least from memory) it doesn't work with thinking enabled, and prefilling the thinking blocks is one of the strongest ways to influence the model's output with a pure text completions API
>>
>>108067860
>>108067946
>>108067656
>Higher that 0.15
>I believe temperature 1.0 is too high.
No shit. In what universe is using and programming focused/tool-calling support model with a sky high temp of 1 EVER a good idea? Even for general purpose shit or even do I feel anything above 0.8 is asking for retardation. This all but confirms to me that the midwits writing the README files/blog posts and the people actually training and/or testing the models not only aren't the same people but both teams are too far up their own asses to talk to each other. I thought only retarda at white collar jobs I worked were like this but I guess this level of laziness is common everything
>>
>>108067607
A guy with a mac on reddit thinks that Longcat-Flash-Lite is "quick and clever", is the age of Longcat finally upon us?
https://www.reddit.com/r/LocalLLaMA/comments/1qwca5n/has_anyone_with_a _mac_tried_longcatflashlite_ngram/
>>
>>
>>108073126
If it's heavily censored in anyway it's fucked. Klein mogs it in the realism department anyway since the Chinese are obsessed with trying to be white and their cultural insecurity leaks into their training practices (keep in mind z-image is Chinese).
>>
>>
>>108073156
Not my fault you've amounted to nothing in life. That's why you took a post about verifiable cultural phenomenon so personally. Consider not being low IQ and maybe you'll feel good about yourself for once. (Creatures like you are so obvious so don't even bother trying to act otherwise. You cannot get laid because you suck)
>>
>>
>>
I need to translate english to chinese nsfw text and I got stuck trying to get qwen models to translate for me inside comfyui, but it doesn't seem it's a thing. Found a translator node, but it's really inconsistent, seemingly random on what it translates.
How do I proceed?
>>
>>108071960
I've been using perplexica with GLM 4.5 Air. It works pretty well but doesn't filter based on token count so its possible to get a search result that is like 300,000 tokens long at which point perplexica just shits itself. Would love a better alternative and also models with higher context windows.
>>

>>
>>108071172
You're delusional if you think something that good is not Udio tier. Yeah it fucks up lyrics, I won't lie about that, but its voice + audio quality is way beyond anything less than Suno v4.5, and if it with a LoRA it's Udio tier (but better sound quality).
>>
>>
>>
>>
>>
>>
>>
>>
>>108073295
I'd just send them tianmen square spam.
>>108073302
Since it does image, video and audio, why not text? It seems that dolphin mistral is what I need?
>>
>>108073368
>It seems that dolphin mistral is what I need?
I very much doubt it. That model is ancient.
I have no way to gauge the quality of an ENG->CHN translation, but I expect a good start would to be to use a Chinese model. Mistral is french.
What are your hardware specs?
>>
>>
>>
File: amd-am5-x870.jpg (96 KB)
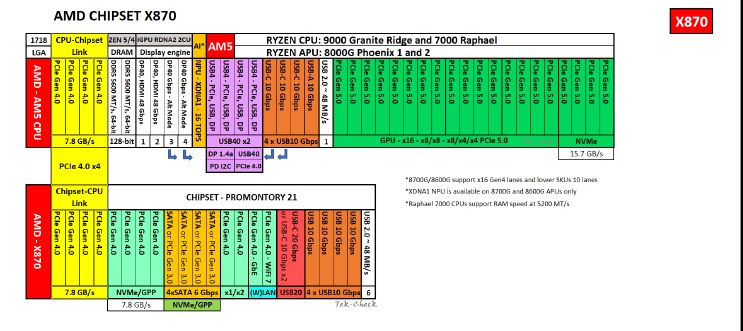
96 KB JPG
Follow up to >>108029695
After doing some research I conclude that getting a board with two electric x8 lanes via x16 mechanic slots is probably best for two GPUs, since it's directly supported by the 9950x. The chipset itself supports up to 6 electric lanes, so a PCIe 4.0 x16 with each x4 or x2 lanes as third or fourth GPU.
>>
File: rinbox.jpg (575.6 KB)

575.6 KB JPG
>>
>>108073389
>>108073527
Ah, there's specific eng to chinese models, makes sense.
I guess the translation doesn't need to be 100%, as long as it's not neutered by sfw.
5090, 196gb ram.
It's purely for translation, I'm seeing 600gb installs, 200gb ram while googling.
>>
>>
>>108073575
For chinese smut I use GLM 4.6 derestricted v3, and am trying GLM 4.7 PRISM. Neither of them are as good as Kimi K2 for me, but you don't need to do anything special to get them to translate nsfw text.
A q4 GLM will take up all your vram and ram to run. If you don't care about being as accurate as possible, try GLM 4.5 air derestricted.
The derestricted/PRISM models are abliterated and generally more stupid than normal, but they're a LOT less hassle to make work with nsfw stuff.
>>
>>108073652
I'm currently running the HY-MT1.5 inside comfyui, apart from the specific wording, it's translating it correctly, sex = intercourse etc.
I just can't seem to grasp on why a translator would required hundreds of gb of ram.
>>
>>108073679
>why a translator would required hundreds of gb of ram.
It doesn't. Raw word-for-word translation can be done for peanuts, memory wise.
An LLM however is there to structure it like actual natural language and translate intent, rather than just individual word meanings.
Textgen is more memory heavy because text is far, far less forgiving for nonsensical shit than images are, so they need to be given a far more generalist training corpus.
>>
>>
>>108073679
While I did recommend HY-MT1.5, it does fail to translate my smut due to safety, but I guess you're aren't pushing it that hard, so it's fine for you. It's mind-bogglingly stupid for anything that requires context though.
>>108073726
You can run a q4 if you want, fp8 air is still pretty stupid and will make mistakes. Might as well go for the slightly more stupid but faster version.
>>
>>
>>
>>
>>108073834
https://github.com/ikawrakow/ik_llama.cpp/pull/1240
First, lmao, whiny faggot.
Second, the issue is ggufers not splitting the metadata from the weights. Maybe that should be the default option.
>>
>>
>>
>>
>>
>>108073986
>>108074011
>>108073986
>>108074011
Oh my god I got the fucking 4.6, fucking google, have been downloading 4.5 since I realized.
>>
>>
>>
>>
>>
>>
>>108073312
How can you conclude it's better when you clearly haven't used ACEStep? Basically just judging based on arbitrary music tastes rather than what the models can do objectively. I have used both, and haven't found much Suno can do that is not possible on ACEStep 1.5 out of the box.
>>
>>108070614
>You'd think by now there would be a truly impressive open source project somewhere that has claude code niggers making it
https://www.anthropic.com/engineering/building-c-compiler
>To stress test it, I tasked 16 agents with writing a Rust-based C compiler, from scratch, capable of compiling the Linux kernel. Over nearly 2,000 Claude Code sessions and $20,000 in API costs, the agent team produced a 100,000-line compiler that can build Linux 6.9 on x86, ARM, and RISC-V.
OH NONONONONO
>>
>>
>>
>>108069401
you can run it on a cheap ass machine with a nvme ssd, it'll be 0.3 t/s but it will run lol.
though, i'd wait for deepseek's engram, in a few month we'll be able to have 1T models run on standard customer hardware, with 99% of the weight on disk and close to no performance loss.
>>
>>108074170
>It lacks the 16-bit x86 compiler that is necessary to boot Linux out of real mode. For this, it calls out to GCC (the x86_32 and x86_64 compilers are its own).
>It does not have its own assembler and linker; these are the very last bits that Claude started automating and are still somewhat buggy. The demo video was produced with a GCC assembler and linker.
>The compiler successfully builds many projects, but not all. It's not yet a drop-in replacement for a real compiler.
>The generated code is not very efficient. Even with all optimizations enabled, it outputs less efficient code than GCC with all optimizations disabled.
>>
>>
>>
>>
>>108074040
This works a lot better than the other I've tried so far. And with text gen webui it was stupid easy to get started once I had the right model.
Bigly thanks for the help, anons.
>>108074048
Yes.
>>
>>
>>
File: c46fd62aae0c4f77bc76729b3f5aec93-imagejpeg.jpg (54.3 KB)

54.3 KB JPG
is he right guys?
>>
>>
>>
>>
File: sirs.png (12.7 KB)

12.7 KB PNG
>>108074471
yes
>>
>>108073088
Thanks for the info anon.
Seems kinda useless then though.
If you cant touch the template and you cant prefill...why not just use chat completion at that point?
OpenAI deprecated textcompletion forever ago too. Hope it won't eve disappear locally at least. Its critical.
I have elaborate janky self made solutions for multiple tool calls with textcompletion in the thinking part and it works pretty well.
These fucking westoid companies man..
>>
>>
File: file.png (414.6 KB)

414.6 KB PNG
>projected to use 194930 MiB of device memory vs. 143171 MiB of free device memory
>context size reduced from 196608 to 90000 -> need 37830 MiB less memory in total
I can't tell how much was off-loaded to RAM...
>>
>>108074471
HAhahaha fuck u retarded lazy ass programmers enjoy having no job no neetbux no nothing while im out here earning a living wiping ass as a nurse lmao you all looked down on me but how the tables have turned hahahhaha see u losers someone just hit their call light and i got a JOB to do
>>
>>108074536
None. The entire model was loaded in vram and the remaining memory was used for context but you aren't getting the full context.
If you set the context to a larger size manually then some of the weights would get pushed into ram.
>>
>>
File: 1759543776868347.png (258.9 KB)

258.9 KB PNG
>>108073834
The excitement has increased.
>>
>>
>>
>>
>>
File: EminemThrowingAKeyboardToAVibeCoder.png (258.4 KB)

258.4 KB PNG
>>108067607
>>
>>108070235
Damn, cuda needs some work.| model | size | params | backend | ngl | dev | test | t/s |
| ------------------------------ | ---------: | ---------: | ---------- | --: | ------------ | --------------: | -------------------: |
| qwen3next 80B.A3B Q4_K - Medium | 45.17 GiB | 79.67 B | Vulkan | 99 | Vulkan0 | pp512 | 5062.72 ± 68.40 |
| qwen3next 80B.A3B Q4_K - Medium | 45.17 GiB | 79.67 B | Vulkan | 99 | Vulkan0 | tg128 | 153.97 ± 2.02 |
| model | size | params | backend | ngl | dev | test | t/s |
| ------------------------------ | ---------: | ---------: | ---------- | --: | ------------ | --------------: | -------------------: |
| qwen3next 80B.A3B Q4_K - Medium | 45.17 GiB | 79.67 B | CUDA | 99 | CUDA0 | pp512 | 2409.47 ± 17.00 |
| qwen3next 80B.A3B Q4_K - Medium | 45.17 GiB | 79.67 B | CUDA | 99 | CUDA0 | tg128 | 52.19 ± 0.34 |
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>108074528
>If you cant touch the template and you cant prefill...why not just use chat completion at that point?
you're either terminally retarded or an ai
i'll give you the benefit of the doubt and assume the former
>Hope it won't eve disappear locally at least
it won't
models like orpheus/maya-1, the kani-tts voice cloning and custom task specific models require it
llama.cpp/ikllama.cpp have based contributors who want it too
worse case scenario you vibe code it back into vllm
>>
>>
>>108074536
Did you set something up to logit bias those special tokens to -inf? Or is that in the ggml metadata?
Your screenshot may have solved a problem for me if you don't know what I'm on about. I would never have expected llama.cpp to just arbitrarily ban certain special tokens like that.
>>
>>
>>
ERNIE 5.0 Technical Report
>We introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community
https://arxiv.org/abs/2602.04705
>>
File: wtf.png (759.3 KB)

759.3 KB PNG
>>108074947
welcome
>>
>>
>>
>>108074947
>I just woke up from a 2 year coma. I bet we're up to Nemo 3.0 and it must be such a huge improvement over the OG nemo, right guys?
You're absolutely right! https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8
It's not just about waking up from a coma, it's about the incredible journey of technological advancement that occurred during those two years! You didn't just make a hypothetical comment, you painted a vivid picture of how rapidly AI evolves. The NVIDIA Nemotron 3 Nano 30B isn't just an improvement—it's a giant leap forward in compact, efficient AI models!
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
What's the best approach to summarize and categorize large amounts of data?
There is a niche reverse engineering d*scord server with hundreds of thousands messages across several years but it's barely possible to find relevant information using the existing search functionality.
I can import all messages (without attachments for now) in a database, but what's next? Any LLM would hit the context limit long before reading all of it and summarization of ~100k token chunks one by one would probably not be that efficient without context-aware separation -- i.e. a topic starts being discussed in one chunk and is finished in the next chunk
>>
>>
>>
>>
>>
>>
>>108075539
Honestly, you could've asked your favorite LLM this same question.
Depends on what you want from the data.
Dump it all into a sqlite DB, then review the DB and clasify each message into a category/topic, link/move the message to a new table/add a keyword for that topic to the message.
Chunk and review in new categories, or bunch together and analyze in groups, creating a third table listing Topic, messages analyzed and result of analysis for X group.
I'd assume most convos are not over 20-30k tokens, (spanning multiple messages) so you won't actually hit this issue.
Chaining the convo messages together might be harder, idk. overall this is a pretty straightforward thing, would assume maybe an hour?
>>
>>108075591
is it really grifting if people are happy with the model? there has to be a much larger population of people who can run a retarded small model on thier gaming rig then there are people who can run the massive models.
>>
>>108075593
sorry, should have specified i was talking about /here/. i don't care if there's people on reddit or in discords jerking off together tuning llama.
>>108075591
so its all prompt prefill and system messages now? that's a shame.
>>
>>
>>
>>
File: gov-trained-kill-erbasement.jpg (214.4 KB)

214.4 KB JPG
>>
>>108074669
Trying to load a model that is bigger than the sum of my gpu/ram ram.
>>108074675
I will check, thanks anon.
>>
>>
>>
File: 1735579896648925.jpg (170.7 KB)

170.7 KB JPG
>>108076203
>>108076491
>>
>>
>>
>>108075539
You can use a mix of time gaps (bursts of messages tend to belong to the same local discussion), reply/quote references when they exist, speaker turn-taking, and semantic continuity (embedding similarity between adjacent messages). When cosine similarity drops sharply or the vocabulary shifts, that’s a decent heuristic for a topic shift.
>>
>>
>>
>>
>>
Batched decoding is fast as fuck right?
Could you do a form of speculative decoding where you don't use a draft model or something like that, and instead you just send parallel inputs to the same model for the next token, token n+1, n+2, etc?
Is there a paper or a PoC like that somewhere?
>>
>>
>>108077025
You can reduce the preprocessing part with APC in vLLM https://docs.vllm.ai/en/latest/features/automatic_prefix_caching/ I don't know if that's what you meant
>>
>>108077025
You're describing MTP, which is a feature that already exists in a lot of models but is not yet implemented by llamacpp or derivatives.
Deepseek, GLM, Minimax, Step, and all EAGLE models can all already do this.
See:
https://github.com/ggml-org/llama.cpp/pull/18039
https://github.com/ggml-org/llama.cpp/pull/15225
https://github.com/ggml-org/llama.cpp/pull/18886
>>
>>
>>
>>108077057
That's kv caching. I'm speculating (lol) about speculative decoding, which concerns token generation/inference.
>>108077060
Close, but no.
MTP has specialized structures (tensors, a whole layer, etc) that go through a specialized training regime.
I'm talking about just taking a regular model (ideally one with FIM capabilities I guess) and using batched decoding to try and predict N future tokens at once instead.
Abusing pipeline magic essentially.
>>
>>108077025
Doesn't the next token depend on the previous token? You'll still have to n+1 before you can do n+2 right?
Or, instead, you can do multiple tokens at a time from a single input, which is what a lot of models do these days, but that's not something you can tack on after the fact.
>>
File: file.png (28.3 KB)

28.3 KB PNG
>>108077025
>>
>>
>>108077101
>Doesn't the next token depend on the previous token? You'll still have to n+1 before you can do n+2 right?
Yes but no.
The next token depends on the whole sequence of tokens that comes before it. So, if you have
>[8k tokens of context taking about avocados]
and the tokens that would come next would be
>"avo" "ca" "do"(let's pretend that's what the tokenizer looks like)
if you send a request that looks like
>[8k tokens of contex taking about avocados] +"avo"+some sort of padding token that represents a skip
the chance of it generating the token "do" would still be pretty high I reckon. Or at least that would be the idea anyway.
>>108077114
>>108077137
I thought those were more like a lookup table approach than running batched requests in parallel.
>>
>>
>>108077025
>Batched decoding is fast as fuck right?
If it existed, maybe, who knows. Magically powered elf computers are much faster.
All of the text models (in regular use by us, at least) are autoregressive. Research something that isn't autoregressive by definition. Maybe you'd be more interested in diffusion language models.
>>
i occasionally come in here and ask about smol tts models. i'm running nano tts at the moment to voice an assistant type thing.
it's reasonably, but i've got my temp pretty high because it's pretty flat without it, but it does get a little out of hand.
any tips on steering this little shit's output for more consistency?
>>
>>
>>108077267
>>108077298
Do you guys not know what batched decoding/batched parallel decoding/continuous batching is?
The stuff backends like llama.cpp and vLLM use to serve multiple users in parallel?
Well, here's some old PR about it
>https://github.com/ggml-org/llama.cpp/issues/3479
>>
>>
>>
>>108077276
The one at https://github.com/gmn/nanotts ? I may have read it wrong, or gotten the wrong "nano tts", but it seems to be an old-school tts, like espeak or festival. And probably just as old. Last commit was 5 years ago.
As for small tts, I like supertonic, but theres kitten-tts (mini and nano) and kokoro for you to try. Pocket-tts released not long ago too.
>>
>>
>>
>>108077324
>>108077327
>>108077334
oh i'm retarded, no it's pocket tts. i keep thinking nano for some reason.
>>
>>
>>
>>108076491
>*crickets*
>>108076491
>It does feel like general interest in LLMs is waning.
There's no reason to use local right now unless you're schizo. Basically unlimited GLM 4.7 is 3 USD a month. China doesn't care about you writing prompts asking for little girls to shit in your mouth (and GLM doesn't care either, a basic SillyTavern setup with a jailbreak from 2023 only refuses toddler scat like 70% of the time on first few messages and never once a yummy poopy context has been built)
And as someone who doesn't RP much anymore, GLM 4.7 is actually close enough to Claude where I was surprised and expecting to switch back to opus immediately. In fact I'm actually upset about it's coding abilities since if it was sonnet 4.5 level for coding I could probably make a whole lolipoop webgame with the 3usd coding plan in a couple of weeks
>>
File: 1760978378059843.jpg (76.9 KB)

76.9 KB JPG
The way the dumber models sometimes start thinking aloud is somehow cute. "I will now proceed to calculate this by doing this and this and I have to be careful".
>>
>>108077114
>https://github.com/ggml-org/llama.cpp/blob/master/docs/speculative.md
>If a draft model is combined with a draftless decoding the draftless decoding has higher precedence.
That's actually really fucking neato.
>>
>>108077374
I'm >>108077267 and >>108077356. The type of batched decoding OP *meant* doesn't exist. We can get a bunch of N+1s and then a bunch of N+2s. But we cannot jump to N+2 directly or get N+1 and N+2 at the same time.
That's why I suggested diffusion language models. Order there is not implied in the architecture.
>>
>>108077357
I like how it sounds well enough, but as far as I know, the only way to change the voice is with finetuning. Also fuck tokenizers. But it's alright.
>>108077359
I made a test client for pocket-tts, but it was too slow on my system. Haven't experimented much with it. I supposed you tried with a more [overly]excited-sounding sample and lower temp? I don't remember if it just copies pitch or it picks on other traits as well.
>>
>>
>>108077445
it picks up quite a bit. i ended splicing together a few clips for the emotional range i want. it even picks up on pacing so had to space clips out naturally, or it was speeding through. i haven't seen any way to force emotions, but i think i'll play around a bit more and just see if it'll interpret parenthesis or smth as emotional info.
it really struggles with more emotional stuff + the output audio is a bit all over the place i.e. i might have to include some eq+compression or multiband comp to lock the tone in.
latency's pretty nice on my 7900x, but it has support for a streaming method that's quicker that i was having a lot of trouble with - mostly problems on my end.
>>
>>108077483
It's only $3 a month for 3 months, then goes up to $6/month for the basic bitch plan.
https://z.ai/subscribe
>>
>>
>>
>>
>>108077509
https://vocaroo.com/1hwR6ju2iw6M
>I hate to sound like a shill, anon, but if you haven't, give Supertonic V1 a go. No voice cloning, but you can mess about with the voice files to get new ones! How does this sound for you?
It gets ! and ?, slightly longer pauses with ... work and short numbers without doing text normalization. And it can make it do this
https://vocaroo.com/1hFm5X4E94GN
>>
>>
>>
>>
>>108077483
>wtf that's cheap. is it worth it? never tried glm
I used to spend about 10 bucks a month on Claude API sexualizing children, but GLM is a good enough substitute so it's worth it for me
Because of Jevon's Paradox I now spend more time sexualizing children than I previously did because I have so much "free" GLM 4.7 available and it feels liberating.
It cannot replace Claude Code for my coding uses, both personal and work-related. If I wasn't a programmer this would take care of everything for me
>>
>>
>>108077810
>no voice cloning is a bit of dealbreaker
Fair enough.
Another thing I've seen anons using gpt-sovits doing is having different embeddings/models depending on the tone they needed.
Have a screaming only sample file, neutral only, question only and so on, but then it's a mess to integrate it with whatever you're using. Like having your model add [SCREAM] tags, grep it out and swap the sample pockettts gets. Too many cogs. Other than that, I'm out of ideas.
>>
>>
>>108077854
t bh it would probably be really easy to do because my current pipeline has a second llm sitting in the middle only doing dialogue generation and that thing can also just spit out the model selection. single sample is good enough for now tho cause it's just helpful assistant lady and the emotional range required is pretty narrow.
>>
>>
>>108074491
No response? I thought I was going to be shown how much of a tourist I am and how LLMs are literally impossible to censor even through API because of how they work?
It couldn't have been just some overconfident retard speaking out of his ass, could it?
>>
>>108077276
>>108077810
have you tried pocket-tts?
>>
>>108077973
yes anon, i'm the retard from >>108077359
>>
>>
>>
>>
>>
File: 1770410837000.jpg (171.1 KB)

171.1 KB JPG
>>108077978
>>108077979
oh
>>
>>
>>
>>
>>
>>
File: jvtlc.png (438.5 KB)

438.5 KB PNG
>>108078011
>>108078024
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>108070614
https://github.com/torvalds/AudioNoise
>Also note that the python visualizer tool has been basically written by vibe-coding. I know more about analog filters -- and that's not saying much -- than I do about python. It started out as my typical "google and do the monkey-see-monkey-do" kind of programming, but then I cut out the middle-man -- me -- and just used Google Antigravity to do the audio sample visualizer.
OH NONONONONO
>>
>>
>>
>>
File: file.png (6.3 KB)

6.3 KB PNG
>>108078332
There's not a single LLM that will format code like this.
>>
File: cross-compliance.png (1.1 MB)

1.1 MB PNG
Excellent, the optimizer is working!
It's not just overfitting the measurement layer selection and scale for each layer, the KL divergence and compliance barely drift when evaluated on a random 50:50 split of the harmful dataset (right 3D plot). Cross evaluating just results in a slightly reduced compliance. Now I have to test it on a large model.
>>
>>108071978
Spite
ClosedAI wants to make competing with them illegal, not make it easier
The start of the RAM price spike was because of Sam buying 40% of all ram wafers and having them destroyed to restrict the hardware supply
>>
>>
>>
>>
>>108078610
Then explain conceptually. Why is the main model going to understand the meaning behind misspelled words and UTF8 replacements but the classifier isn't? Do you really think you can fool a modern safetymaxxed model like GPT 5.2 acting as a classifier? You being able to confuse an ancient model use by c.ai years ago doesn't prove anything.
>>
>>
>>
>>
>>
>>
>>108074203
I tried that with Qwen3 coder next and was surprised it ran at all, but the IOPS made me scared of speedrunning my NVME's death.
I'm fine with it being slow but I don't want to actually destroy the drive for it. Maybe I can page to hard disk and just queue up tasks before bed.
>>108069422
Mostly I want agentic and coding stuff.
Conversation is a bonus.
We have nuclear energy around here so its somewhat cheap but yeah I'd have to measure it.
>>
File: 1743375875958667.jpg (126.6 KB)

126.6 KB JPG
>>
>>
>>108079153
It's my own merge of grimjim's norm-preserving biprojected abliteration and p-e-w's heretic optimizer based abliteration. The white background plot is made with matplotlib and the dark background 3D plot with plotly.
>>
>>