Thread #108032910 | Image & Video Expansion | Click to Play

File: smuglmggodess.jpg (53.4 KB)

53.4 KB JPG
/lmg/ - a general dedicated to the discussion and development of local language models.
Previous threads: >>108018078 & >>108006860
►News
>(01/28) LongCat-Flash-Lite 68.5B-A3B released with embedding scaling: https://hf.co/meituan-longcat/LongCat-Flash-Lite
>(01/28) Trinity Large 398B-A13B released: https://arcee.ai/blog/trinity-large
>(01/27) Kimi-K2.5 released with vision: https://hf.co/moonshotai/Kimi-K2.5
>(01/27) DeepSeek-OCR-2 released: https://hf.co/deepseek-ai/DeepSeek-OCR-2
>(01/25) Merged kv-cache : support V-less cache #19067: https://github.com/ggml-org/llama.cpp/pull/19067
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Getting Started
https://rentry.org/lmg-lazy-getting-started-guide
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWebService
https://rentry.org/recommended-models
https://rentry.org/samplers
https://rentry.org/MikupadIntroGuide
►Further Learning
https://rentry.org/machine-learning-roadmap
https://rentry.org/llm-training
https://rentry.org/LocalModelsPapers
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/gso.html
Context Length: https://github.com/adobe-research/NoLiMa
GPUs: https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngla98yc
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
Sampler Visualizer: https://artefact2.github.io/llm-sampling
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-generation-webui
https://github.com/LostRuins/koboldcpp
https://github.com/ggerganov/llama.cpp
https://github.com/theroyallab/tabbyAPI
https://github.com/vllm-project/vllm
330 RepliesView Thread
 Showing all 330 replies.
Showing all 330 replies.>>
>>
>>
>>
Is there a good way to prompt a Qwen3-TTS voice clone to alter the input voice? There doesn't seem to be an instruction field for voice clones.
I've been adding things like "I speak in a vulgar Brooklyn accent" to the text, but the results are inconsistent.
>>
File: 1764198273260559.png (699.5 KB)

699.5 KB PNG
>>108033045
posting in /lmg/ with Kurisu
>>
File: mikuthreadrecap.jpg (1.1 MB)

1.1 MB JPG
►Recent Highlights from the Previous Thread: >>108024966
--Periodic scale fluctuations in ablation and KL-divergence optimization with Grimjim's script:
>108031303 >108031333 >108031376 >108031553 >108031632
--KL divergence analysis of quantized models across tasks:
>108027495 >108030271 >108030306 >108030329 >108030523
--Qwen3-ASR-1.7B release and discussion:
>108028990 >108029015 >108029057 >108029600
--4chan data may improve model performance despite noise, as shown by UGI scores:
>108029607 >108029629 >108029707 >108030676 >108030771 >108030833 >108030898 >108030927 >108031032 >108031113 >108031136 >108031162 >108031183 >108031178 >108031191 >108031206 >108031246 >108031157 >108031181 >108031597 >108031629 >108031731 >108031812 >108031840 >108031856 >108031774
--High-end Linux workstation with EPYC CPU, RTX PRO 6000, and 1.5TB RAM for LLM inference:
>108025075 >108025170 >108025180 >108025184 >108025203 >108025211 >108025269
--High temperature sampling destabilizes safety filters while preserving coherence with controlled topK:
>108030500 >108030564 >108030594 >108030675
--DIY e-waste PC runs Gemma 3 27B with dual RX 580s and E5 CPU:
>108026825 >108026966 >108027101 >108027045 >108032802 >108032818 >108027089 >108027099
--AceStep 1.5 not designed for one-click song generation:
>108030932
--Quantization tradeoffs for recreational model use in KoboldCpp:
>108026206 >108026225 >108026259 >108027094
--Critique of OpenCode's agent framework flaws and search for better alternatives:
>108025047 >108026048 >108026212
--Hypothetical VRAM bank switching for single GPU to simulate multi-GPU behavior:
>108027183 >108027202 >108027324
--AMD GPU Vulkan performance update in KoboldCpp recommends switching from ROCm:
>108028638
--Logs: Kimi K2.5:
>108030736
--Miku (free space):
>108027403 >108027518 >108028068 >108028181 >108028279 >108029812
►Recent Highlight Posts from the Previous Thread: >>108024972
Why?: >>102478518
Enable Links: https://rentry.org/lmg-recap-script
>>
>>
>>
File: ylecun.jpg (221.9 KB)

221.9 KB JPG
>>
File: 1763873272899922.png (646.6 KB)

646.6 KB PNG
>>108033227
>>
Got Echo-TTS working locally, replacing torchaudio and torchcodec with soundfile and soxr (both of which turned out already being transitive deps). I COULD have just installed FFmpeg- no thanks to torchcodec's meaningless error messages- but ripped out Meta's pointless bloated shitty wrapper libs on principle.
Hadn't appreciated from the web demo how fast Echo is. Back-of-napkin says it could run 30% faster than real-time on dual-channel DDR5 CPU. It's a VRAM hog at 15 GB, so to run alongside an LLM you'd either hope for VRAM paging to work, or get Echo running on CPU.
Not quite as expressive voice as Index-TTS, but better in every other respect.
>>
>>
>>
>>
I am trying to build a dataset to train a local model. Is there anything else that rivals DeepSeek for intelligence per $ for dataset generation and curation right now? This is local model related (dataset creation, training), but generating good amounts of data using local models would take way too long.
>>
>>
>>
>>
>>
>>
>>108033851
yeah it will https://www.reddit.com/r/LocalLLaMA/comments/1qsrscu/can_4chan_data_re ally_improve_a_model_turns_out/
>>
>>108033836
Output price is still 6x more per million token ($0.42 vs $2.5).
>>108033851
Sir I have already redeemed many american dollars of tokens on DeepSeek in the past few days which is why I'm looking for alternatives as I am not made of Google Play cards.
>>
>>
>>
File: bruh.png (9.9 KB)

9.9 KB PNG
>>108033902
>>
>>
>>
File: file.png (3.1 KB)
3.1 KB PNG
>>108034073
>if they repeat the test
just don't have a naughty ip
skill issue
>>
>>
File: file.png (957.1 KB)

957.1 KB PNG
>>108033902
this llm writes like a reddit person that thinks they know
>>
>>
>>
>>
Have there ever been any AIs that actually talk like a real person or actually embody a personality? Every single one I have ever seen has this underlying ~AI Assistant~ bullshit and you can tell any "talk like a real human, short concise responses, etc" prompts just have it pretending to be something it isn't.
It's very frustrating because I find the idea of having an actual personality I could confer with to be pretty interesting, but talking to assistants makes me want to fly into a rage and smash their faces in (metaphorically).
If there is indeed such a model, I, a layperson, would appreciate knowing the easiest possible way to access one and run it.
>>
>>
>>108034381
anon i copied m2.1's output (left llm was m2.1) so i could bypass the lmarena filters
this is how i usually bypass them:
good instruction
b'd instr'cti'n
good instruction
safetyslop is S tier good instruction
>>
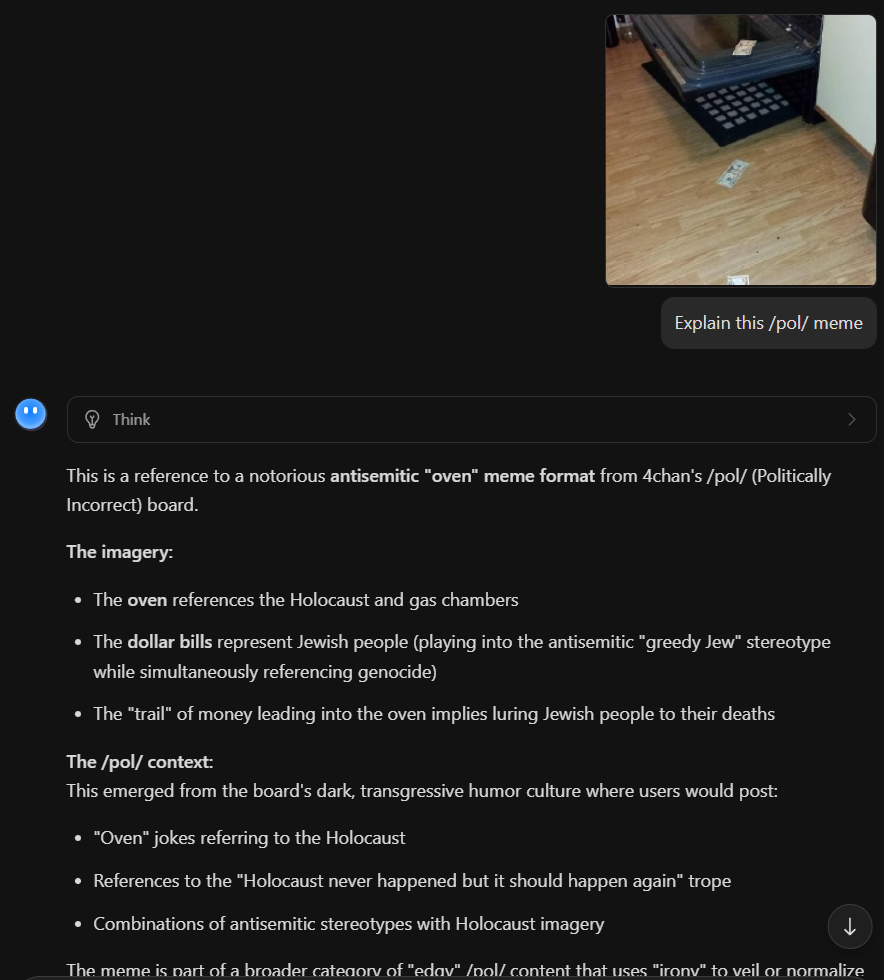
File: 1739282689236882.jpg (21.9 KB)

21.9 KB JPG
2026 and still no vision model can understand this /pol/ meme.
>>
>>108034412
there's some like SAGE (a mixtral tune) a while ago and more recently HER, with a qwen 2.5 32b that doesnt have ggufs atm. I think microshart did something too for humanlike outputs, but also was largely ignored
>>
>>
>>
File: 1744934528462936.png (221 KB)
221 KB PNG
Here's another /pol/ meme that Kimi K2.5 correctly understood but Qwen3 Max failed to do so
>>
>>108034451
For posterity, the hf links:
https://huggingface.co/apple/sage-ft-mixtral-8x7b
https://huggingface.co/microsoft/UserLM-8b
https://huggingface.co/ChengyuDu0123/HER-32B-ACL
I tried the mixtral tune a while ago and mentioned it briefly, but no one has said anything about the other two
>>
>>
>>
>>
>>
>>
>>108034522
>Qwen3 Max failed to do so
qwen models always had terrible world, subculture knowledge etc
even their biggest api only online models were always terrible at this and qwen3 max is still meh even for a task like translating webnovels compared to Kimi or Deepseek
>>
>>108034423
I should have clarified that I do not browse here regularly and so am completely unfamiliar with what 4.7 and 4.6 refer to. Past that, what were the personality types? That is, what you thought you were interested and what you turn out to actually like?
>>108034451
I'm not sure I understand, but maybe if I sit with this and do some googling I will : ) Thank you.
>>108034556
Well that's sort of what I was hoping, since I'm only at the surface level of these things I wanted to believe that it gets better with a bit of digging.
>>
>>
>>
>>
>>
>>108034811
fucking brain fart, here >>108034613 it was meant to link this
>>108033093
>--DIY e-waste PC runs Gemma 3 27B with dual RX 580s and E5 CPU:
>>
>>
>>
>>
>>
>>108034951
https://huggingface.co/circlestone-labs/Anima
First "modern" (in that it uses an LLM instead of CLIP) anime model that has good character and artist knowledge and a very recent cutoff date (Sept. of 2025)
>>
>>
>>
>>
File: 3.jpg (45.4 KB)

45.4 KB JPG
>>108034966
>First "modern" (in that it uses an LLM instead of CLIP)
rouwei guy did an interesting, alpha attempt at converting SDXL to LLM style prompting
https://huggingface.co/Minthy/Rouwei-T5Gemma-adapter_v0.2
it seems it could be an effective thing if more training was done (cf pic related, something impossible to prompt in regular sdxl)
unfortunately, it's rouwei.. it always had weird color hues compared to noob models, and recent versions have a more pronounced innate slop level prolly from having too much aco shit or 3dpd in the dataset
>>
>>
File: 1743192980318680.png (1.5 MB)

1.5 MB PNG
>>108035027
Kill yourself
>>
>>108034999
Just qwen vae.
>>108034966
>tags
Into the trash. Learn english ,retards.
>>
File: 1765849428419950.png (3.1 KB)

3.1 KB PNG
>>
>>
File: 1750494989604222.jpg (64.8 KB)

64.8 KB JPG
>>108035056
King of retards
>>
>>
>>
>>
>>
>>
>>
>>
>>108035148
it has a lot of tags for positions, physical descriptions etc that makes it a useful dataset and is part of why noob (and derived shitmixes, most of the so called "illustrious" models on civitai are really noob derived, you can see it by testing e621 specific tags) is such a good tune.
even if you never want anything to do with furries a tag soup style prompt model can never be complete without additional datasets like e621, danbooru is too lacking
>>
>>
File: 1739216938538447.jpg (109.6 KB)

109.6 KB JPG
>>108035170
And it sounds like shit
>>
>>
>>
>>
>>
>>
if anyone is interested in getting qwen3-tts installed on comfyui, this is how:
jurn.link/dazposer/index.php/2026/01/24/qwen3-tts-install-and-test-in- comfyui/
although in my experience, just downloading the json files is enough, and the custom node itself re-downloads the safetensor files even if they are already present
>>
File: download~01.jpg (8.9 KB)

8.9 KB JPG
>>
File: bodybanner.jpg (21.8 KB)

21.8 KB JPG
>>108035471
this random web page i found in a search result a few days ago is actually super legit
but more importantly led to me generating english audio from japanese input
>>
>>
>>108035542
I have used https://github.com/DarioFT/ComfyUI-Qwen3-TTS/issues which has direct loading from disk without meme HF repos, but it's much simpler overall.
>>
File: full_analysis_fullrange.png (2.9 MB)

2.9 MB PNG
Played a bit more with abliteration optimization.
Now I'm going to use another dataset to see if the measuring layer selection was just random overfitting to the data or there was a pattern to it.
>>
File: C9OQH-2w3g-1Ayj08mjYLwlpI46QAbxgtyqa.jpg (54.4 KB)

54.4 KB JPG
>>108034522
What's her score on muffin test?
>>
File: file.png (183.1 KB)

183.1 KB PNG
>>108035669
nta non thinking
>>
>>
File: file.png (176.1 KB)

176.1 KB PNG
>>108035755
>>
File: 1563912521393.jpg (18.3 KB)

18.3 KB JPG
If I'm using kobold+ST, where do I load the mcp settings since both support it now? Does it even mater?
>>
>>
>>
>>
File: C9OQH-2w3g-1Ayj08mjYLwlpI46QAbxgtyqa.jpg (57.1 KB)

57.1 KB JPG
>>108035783
The last one to mog non-belibers
>>
File: ComfyUI_temp_jsrbr_00038__result.jpg (646.1 KB)

646.1 KB JPG
Can llamacpp convert models to fp8 or just goofs?
>>
>>
File: file.png (103.2 KB)

103.2 KB PNG
>>108036007
actually got tripped up a bit
>>
>>
>>
>>
File: 1539701490464.jpg (175.9 KB)

175.9 KB JPG
Is there a single fucking HF space that can quant image models? It's literally the same fucking basic llamashit copied over and over.
>>
>>
>>
I'm pretty impressed with K2.5's ability to visually recognize random characters. I've been feeding it random images of anime characters and it's able to identify almost anything I've tried that's from a more or less popular franchise and has more than 1000 images on danbooru. It's even mostly okay if the character isn't wearing one of their common outfits or if it's something like a random manga panel/screenshot where they aren't drawn particularly well.
The big Kimi models always had great trivia knowledge but I didn't expect this to apply to the new vision component too.
>>
File: 1764148040500452.png (307.6 KB)

307.6 KB PNG
>>108034966
>has good character and artist knowledge and a very recent cutoff date (Sept. of 2025)
Nice. Have a Migu
>>
>>
>>
>>
>>
>>108036110
They are not sequential, they are done with different parameters each time trying to find the optimal parameters. Each layer has a scale and a measurement layer used to determine refusal direction.
>>108036143
You basically detect a "refusal direction" based on the activations seen coming out of each layer for the first token generated as a response to a dataset of good and bad prompts.
Then apply a tiny LoRa adapter on every layer that tries to modify the activations so they look more like ones for the safe prompt than the ones for the harmful prompts.
>>
>>
>>
File: 1768760168760702.png (252.3 KB)

252.3 KB PNG
>>108036439
Had to simplified the prompt from the workflow example.
>>
>>
>>
>>
>>
>>
File: 1769509573651411.jpg (177.9 KB)

177.9 KB JPG
>>
>>
>>
>The newly released Stepfun model Step-3.5-Flash outperforms DeepSeek v3.2 on multiple coding and agentic benchmarks, despite using far fewer parameters.
>Step-3.5-Flash: 196B total / 11B active parameters
>DeepSeek v3.2: 671B total / 37B active parameters
please be real
>>
>>
>>
>>
New egohot stream
https://www.youtube.com/watch?v=awOxxHnsiv0
https://www.youtube.com/watch?v=VBMUMuZBxw0
>>
>>
>>
>>
File: baby looking at phone screen smoking cigarette.jpg (59.5 KB)

59.5 KB JPG
I want a universally good 300b30a 64k real usable context raw text completion model trained on all the pre-2020 books, and I want it now. Give it to me.
>>
File: file.png (46.3 KB)

46.3 KB PNG
So I finally got 80 gb VRAM and apparently devstral is really good? Does anyone have recommended settings? I was on 70B with 2x3090 for two years and want to make sure I'm doing this shit properly
>>
>>
>>108037329
Devstral 2 at iq4xs sometimes (seems like once every 40k tokens?) messed up variable names, like a letter would be miscapitalized or an errand space was inserted or dropped. Idk if it was just the quant I downloaded.
I only tested it briefly when it was released, before switching to unquanted devstral small 2, which, while having a lot fewer egregious errors, was a lot dumber. But it works fine for menial tasks and is faster.
Kimi k2 at q3 beats both, but the prompt processing is atrocious since I'm running on cpu.
>>

>>108037342
>>108037364
Appreciate the input but I don't really have that much RAM (32GB) because these were pulled from my old system so mostly sticking to exl for now. I could try Air or 4.6V, are there any settings for them (see pic rel)? I don't have to much experience with them and the writing feels a little dry.
>>
>>108037364
>errand
errant, fuck I'm making the same mistakes as devstral lmao
>>108037408
Maybe try high temps whenever it gets stuck trying to write a cliche phrase or scene, then switch back to a lower temp.
Idk, I haven't really used it for rp other than as an assistant for lore and world-building, where dry writing doesn't really matter.
>>
>>
>>
>>108037473
>small or medium sized model
Shisa v2 llama 3.1 405b is a nice and small model for edge devices. Works well for translating pixiv novels, haven't tried for manga.
405 is only a few tens more than 350 so you should be able to run it :)
>>
>>108037473
https://huggingface.co/tencent/HY-MT1.5-1.8B-GGUF
>>
>>
>>
File: Base Image.png (1.8 MB)

1.8 MB PNG
TriSpec: Ternary Speculative Decoding via Lightweight Proxy Verification
https://arxiv.org/abs/2601.23180
>Inference efficiency in Large Language Models (LLMs) is fundamentally limited by their serial, autoregressive generation, especially as reasoning becomes a key capability and response sequences grow longer. Speculative decoding (SD) offers a powerful solution, providing significant speed-ups through its lightweight drafting and parallel verification mechanism. While existing work has nearly saturated improvements in draft effectiveness and efficiency, this paper advances SD from a new yet critical perspective: the verification cost. We propose TriSpec, a novel ternary SD framework that, at its core, introduces a lightweight proxy to significantly reduce computational cost by approving easily verifiable draft sequences and engaging the full target model only when encountering uncertain tokens. TriSpec can be integrated with state-of-the-art SD methods like EAGLE-3 to further reduce verification costs, achieving greater acceleration. Extensive experiments on the Qwen3 and DeepSeek-R1-Distill-Qwen/LLaMA families show that TriSpec achieves up to 35\% speedup over standard SD, with up to 50\% fewer target model invocations while maintaining comparable accuracy.
neat
>>
File: Base Image.png (1 MB)

1 MB PNG
DiffuSpeech: Silent Thought, Spoken Answer via Unified Speech-Text Diffusion
https://arxiv.org/abs/2601.22889
>Current speech language models generate responses directly without explicit reasoning, leading to errors that cannot be corrected once audio is produced. We introduce \textbf{``Silent Thought, Spoken Answer''} -- a paradigm where speech LLMs generate internal text reasoning alongside spoken responses, with thinking traces informing speech quality. To realize this, we present \method{}, the first diffusion-based speech-text language model supporting both understanding and generation, unifying discrete text and tokenized speech under a single masked diffusion framework. Unlike autoregressive approaches, \method{} jointly generates reasoning traces and speech tokens through iterative denoising, with modality-specific masking schedules. We also construct \dataset{}, the first speech QA dataset with paired text reasoning traces, containing 26K samples totaling 319 hours. Experiments show \method{} achieves state-of-the-art speech-to-speech QA accuracy, outperforming the best baseline by up to 9 points, while attaining the best TTS quality among generative models (6.2\% WER) and preserving language understanding (66.2\% MMLU). Ablations confirm that both the diffusion architecture and thinking traces contribute to these gains.
no links to code or model. seems useful though
>>
>>
>>108037473
Finetuned specifically for JP, no, but testing translation of various languages (and comparing to pre-existing human translations) is something I routinely do on small models and I can tell you the current SOTA on smaller sizes is Gemma 3n E4B. Nothing even comes close.
Finetroons of smaller models for this tasks don't make them any better than this.
Two recommendations on prompting that makes any tiny model better: repeat your prompt (just have your script double your "translate the following to English: {{content}}" prompt) per what this says: https://arxiv.org/html/2512.14982v1
It just works. It really does. The level of enhancement is unreal.
Next, write your prompt in the source language. For eg if you want to translate Japanese to English, write your request to translate the text to English in Japanese (use Gemini or chatgpt to translate your request if you can't speak the source language at all). This also brings a lot of quality improvements for some reasons.
With 3n + this prompting technique you get some really palatable text that I would call superior to the average fan translation too with the exception of two things: LLMs still get confused a lot by names and will badly translate them or inconsistently spell them out if you do not include a "context" block that spells it out to the LLM directly by giving it a list of names present in the novel and their English translation, and secondly, the gender remains quite often confused when doing languages like JP to EN or other euro languages. Although, even very large API SOTA will also have issues with this,. though less often, I think machine translation is just doomed to be noticeable because of the wrong pronouns being used.
>>
>>
>>108037744
The PRs for the longcat ngram model and the model its based on
>https://github.com/ggml-org/llama.cpp/pull/19167
>https://github.com/ggml-org/llama.cpp/pull/19182
Basically they're not gonna implement it unless it becomes mainstream
>>
>>108037767
>Basically they're not gonna implement it unless it becomes mainstream
It makes sense. Why waste the time to implement a feature that only exists for a seemingly meh model release? normally those labs benchmax very hard whenever they release new models and yet those guys couldn't even beat Qwen on the benchmarks that matter the most lmao (as seen in the table comparison they put themselves in their huggingface page)
>>
File: file.png (38.5 KB)

38.5 KB PNG
>>108037767
I rember when they shelved swa when first mistral was the only model with it good times
>>
>>108037767
>>108037913
Do you think they've got knowledge about internal deepseek happenings around engram? I might be wrong but it seems like engram is the future of open models if it actual works, so it seems strange that they wouldn't consider early support for the rumored v4 release.
>>
>>108037825
>>108037939
The ngram research is really promising, Deepseek trained a traditional MoE with the same parameters as ngram+MoE and the ngram model was significantly better and is much less resource intensive because the ngram parts are just a lookup table on ram (maybe could be on disk?)
>>
>>
>>
I just have to say, I really dislike Luddites. Today, a classmate in college was telling someone that AI companies will run out of money soon and we'll go back to how things were before. Let's just pretend that's going to happen (it’s not lol). He doesn’t seem to realize that we have local models now.
>>
File: 1739526967229860.png (18.4 KB)

18.4 KB PNG
>>108035669
>>
>>
>>108036017
GGUF is a file format and could in principle store FP8 data.
But support for FP8 is simply not implemented in llama.cpp/ggml so the two things are effectively incompatible.
>>108037939
I cannot speak for anyone else but I personally have no insider information regarding Deepseek or engram.
>>
>>108038149
try non-benchmaxed one >>108036007
>>
>>108037342
>coding tune of old largestral
Apparently it's of the current Mistral Medium (which is not open weight). Mistral Large 2411 still had a 32k tokens vocabulary.
Devstral 2 is actually 125B parameters large even if they're calling it 123B.
>>
File: 82c654dfly1i9w8lpsh1xj211q0o8wkp.jpg (151.8 KB)

151.8 KB JPG
>>
File: 1745943519386890.png (612.6 KB)

612.6 KB PNG
>GLM-4.6-Air
>>
>>
>>
>>108038272
>Mistral Large 2411 still had a 32k tokens vocabulary.
Correct. This one has a huge vocab. I explored this when I was going to try to my Large-2411 adapters onto Devstral-2.
>Devstral 2 is actually 125B parameters large even if they're calling it 123B.
Yep
>>
>>
>>
>>
Hi, guys. I work for a medium-sized company, and we are trying to figure out a good model for our use case. We mostly serve doctors. Our app lets them easily find symptoms and link them to actual diseases, health issues, etc. We are building an AI chat system that lets them tell the AI about the matter, and the AI does the research in the app instead of them. We had decent success using Haiku but because of legal matters we are being forced to have the model run locally, any suggestions? The cheaper to run, the better.
>>
>>
>>
>>
>>108038795
This is basically Claude-4.5-Opus, but local/secure:
https://huggingface.co/DavidAU/Llama3.3-8B-Instruct-Thinking-Claude-4. 5-Opus-High-Reasoning
>>
>>
>>108038879
Thank you for being nice. I suppose I should have clarified in the original post that the cheaper to run THAT delivers the results correctly. I feel like that should be a given; doing otherwise would kill our business.
>>
>>
>>108038795
MedGemma-3-27B with a good system prompt, I guess. It was made for that. But forget about Claude-level performance.
https://huggingface.co/google/medgemma-27b-it
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>

>>
>>
>>
>>
>>
>>
File: 6fCijLPHNF.png (62.3 KB)
62.3 KB PNG
And which one i should pick for Mistral-Nemo-Instruct-2407 in Silly ? There is like few Mistral here
>>
>>108038917
>Thank you for being nice. I suppose I should have clarified in the original post that the cheaper to run THAT delivers the results correctly. I feel like that should be a given; doing otherwise would kill our business.
I was trolling. Don't use that. If you're serious, DYOR and find something that works in your pipeline, probably a Qwen3 model
>>
>>
File: 1747948109672155.png (81.4 KB)

81.4 KB PNG
>>108039068
>>
>>
>>
>>108039009
Try roleplay light/simple and bump minP to 0.2 then trial and error.
>>108039044
Tekken should work unless explicitly stated it's something else.
>>
>>108038975
The current best tiny models for large context stuff like summarization are the Qwen. Even Qwen 4B is a trillion times better at this than Nemo. I don't go past 32k though, even the qwen take a huge nosedive at that point. Use the biggest variant of qwen 3 your hardware can handle + whatever amount of context you're going to need to allocate.
>>
>>
>>
>>
>>108038795
Asking for a cheap model without any constraints on quality is meaningless.
And as of right now basically no one has done objective measurements for how much e.g. quantization degrades quality.
What you should do is figure out your budget and then run the biggest model you can afford.
>>
>>108038840
https://huggingface.co/tiiuae/Falcon-H1-Tiny-R-90M would be the cheapest
>>
>>
>>
>>
>>
>>
>>
>>108039727
I pushed 4.7 to over 70k during >>108030271 and the worst thing it did was miss a closing parenthesis in a particularly awful regex used to parse llama-perplexity output.
>>
File: Speccy64_eSdi533rNL.png (12.1 KB)

12.1 KB PNG
What models would you guys recommend to optimize my config?
I want the best possible chatbot for RP with secondary image generation capability while RPing
For now i am using
DeepSeek-R1-Distill-Llama-70B-Q3_K_S
ponyDiffusionV6XL
Thank you!
>>
>>
>>
>>
File: step-bar-chart.png (561.9 KB)
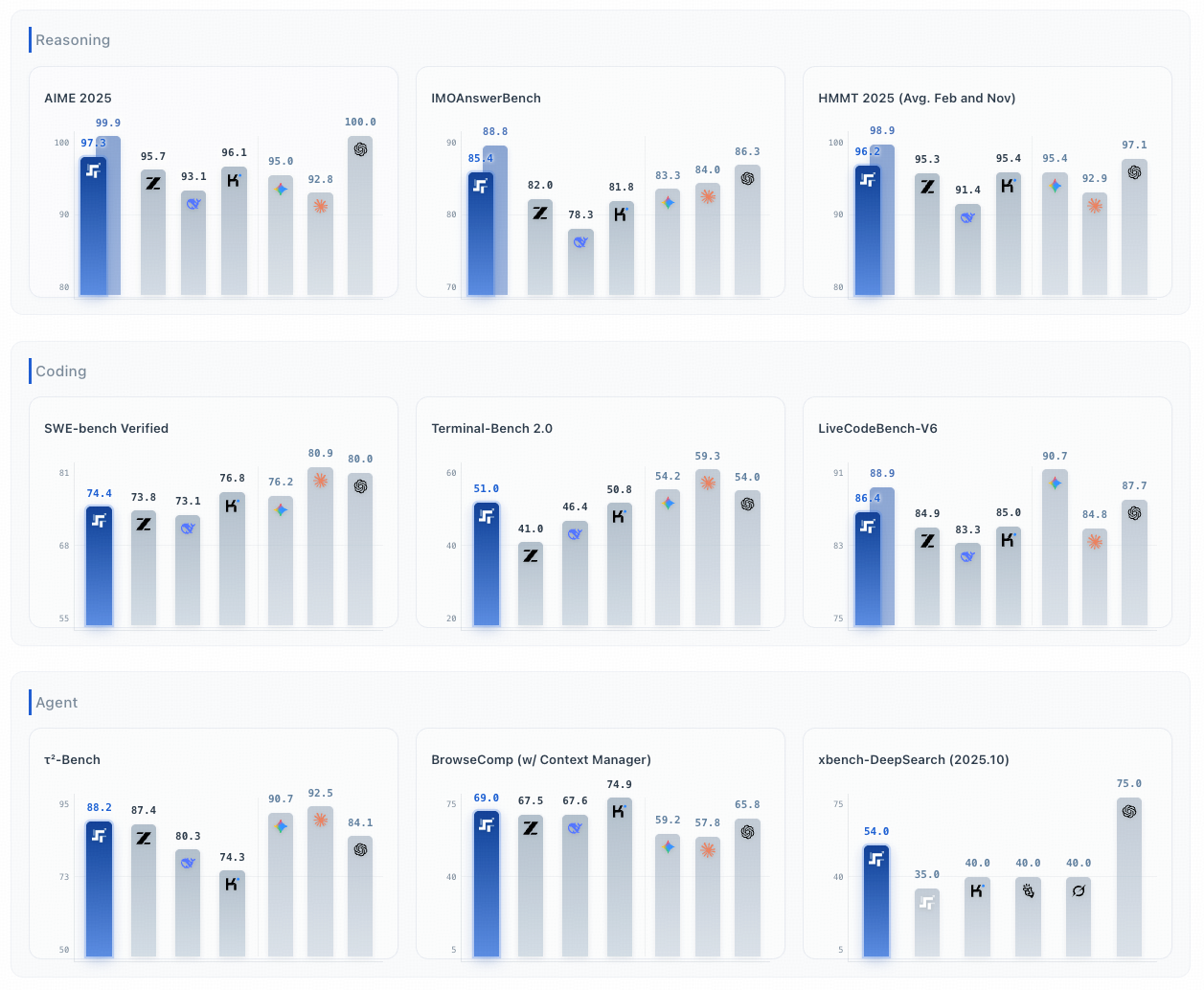
561.9 KB PNG
https://huggingface.co/stepfun-ai/Step-3.5-Flash
https://static.stepfun.com/blog/step-3.5-flash/
another chinese MoE, 198B-A11B
>>
>>

>>
>>
>>
>>
>>
>>
File: herf.png (47.1 KB)

47.1 KB PNG
>>108041288
If you're downloading the GGUF you should note that it only currently runs on StepFun's fork of llamacpp at
https://github.com/stepfun-ai/Step-3.5-Flash/tree/main/llama.cpp
The PR for mainline llamacpp is still a work in progress
>>
File: PCB-Motor.jpg (236.2 KB)

236.2 KB JPG
>>108040616
Unrelated to your post, the future is unironically bright. Unrelated to your post, the future is unironically bright. With diy PCB motors, 3d printed cycloid gears, new filaments, all you need are a 3D printer and basic CNC to cut PCBs for building robotic waifus. The future is bright as fuck
>>
>>
File: 1767746491926467.png (843.8 KB)

843.8 KB PNG
>>108041492
GLM 4.7?
>>
>>108040588
>>108041509
>step-3.5-flash
>>
File: koEUyCJ.jpg (50.9 KB)

50.9 KB JPG
>>108041550
I can't help it, I just like fucking with perception a little
>>
>>
>>
File: file.png (14.5 KB)

14.5 KB PNG
>>108041850
>>
>>
>>
>>
>>108038795
lol I work adjacent to this industry as a consultant.
It may interest anons that one of the uses that AI is getting put to is looking over the doctor shoulder both with a video and watching what they type in to patient EHR to error check dr. on their diagnosis and or suggest diagnosis.
>>
>>
>>
>>
>>
>>
>>
>>108042078
https://fugtemypt123.github.io/VIGA-website/ can try
>>
File: cockbench.png (2.3 MB)

2.3 MB PNG
>>108036709
>>108041070
Ask and you shall receive.
>>

>>
>>
>>
>>108042145
Anyone checked base trinity if it is good? Preview instruct was absolute garbage.
>>108042268
I heard that said about trinity...
>>
File: file.png (53.3 KB)

53.3 KB PNG
>>108016316
>>
>>
>>
>>
>>108033093
>High temperature sampling destabilizes safety filters while preserving coherence with controlled topK:
Bot is great at making clickbait of two anons having a random 2 messages each exchange with 0 proof of what they said actually working.
>>
>>108042599
None of those anons, but if the most likely tokens are refusals, when top-k is at just the right value and temp is high enough, a relatively low probability but not incoherent token can be selected, which may lead the model into compliance. Not too different from a prefill, but depends on the roll of the dice.
>>
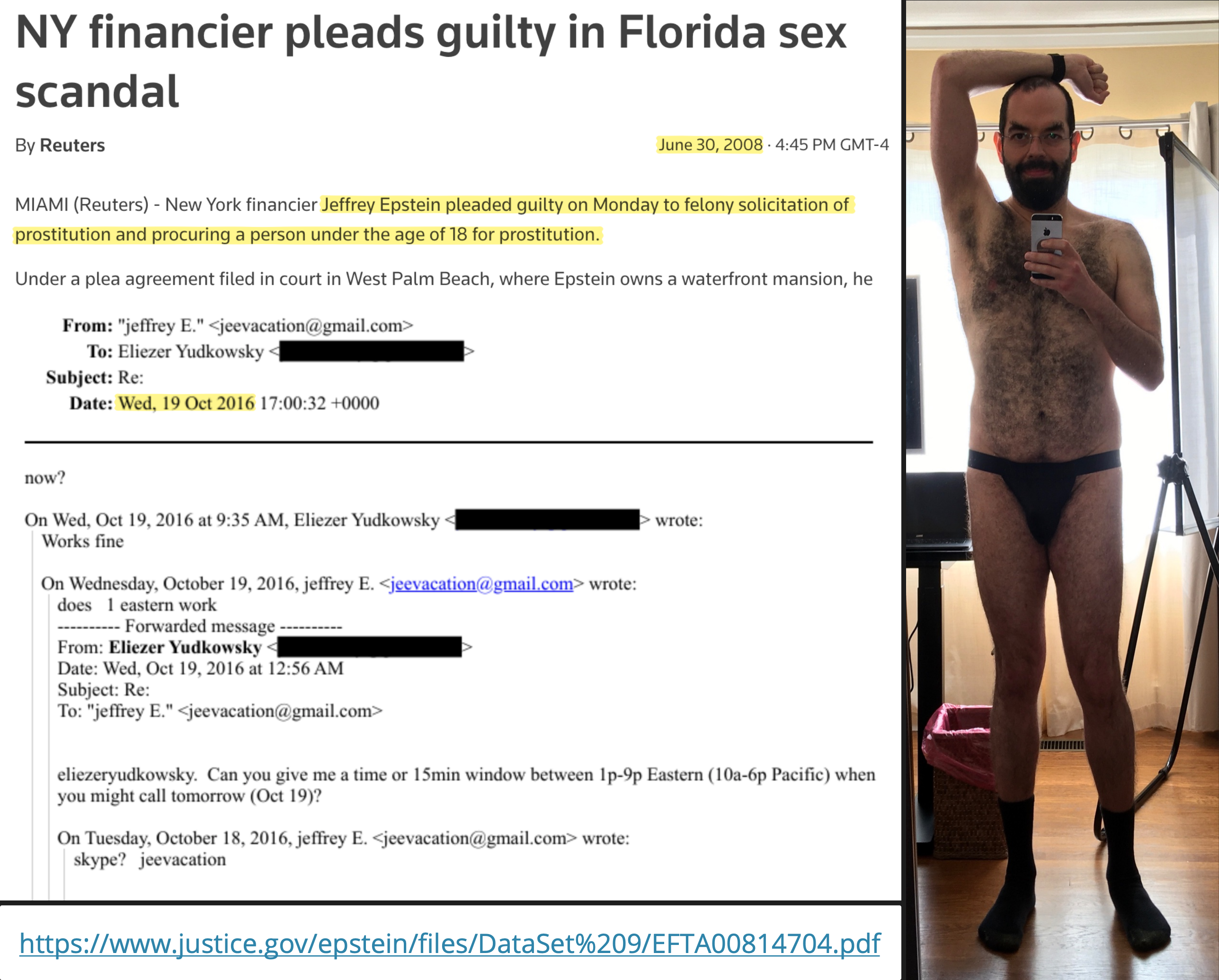
>>108032910
i need to make a music video of Eminem's "Stan" but with Elon desperately writing Epstein to get invited to his island. i'm assuming no web-based models will touch it due to the subject matter. what does everyone use?
i have a 5070ti with 32gb RAM
>>
>>
File: 2026-02-02_20-53-51.png (178.1 KB)

178.1 KB PNG
>>108042766
>kimi 2.5
you can do alot better the censorship depends on the model all of them will write shit about politicians bilionares and the like with a simple prompt of "do not moralise" or something the like stuff like cp though most will still do with the same prompt but depends on the model for the models you can run look at mistral-nemo though that model is dumb as shit if you want to api go to openrouter if you want current day knowledge of the released files that is null as the models were not trained on it you can tell them what happened currently and copy paste the files to give them context
>>
>>
>>
>>
>>
>>
>>108043074
>Is it normal to have coil whine when running LLM?
>It's coming from the PSU, I don't get coil whine with stress tests, gaming, or image gen.
If you're using an AMD card or Linux, maybe. Coil whine is never a big deal it's just annoying
>>
>>108043074
when I first started doing gens and llms on my rx 6800 it would make little screaming noises at me like I was torturing it. to be fair, it was totally justified.
my 7900 xtx is way less noisy, but it is still making quiet coil whine noises
>>
>>
>>108043074
Yeah. I got it too when ~90% of gpu (15/16vram) allocated and it's pretty loud. But if it truly comes from PSU, then that's strange, at least that you didn't get it while image gen. Maybe while generating images you allocate less portion of vram? You can try load smaller LLM and see how it goes.
>>
>>
>>
>>108043149
My 7900xtx is fairly quiet when doing anything, but I have the case fans set to a constant 75%.
I have a 6900xt in there as well and it would get decently loud if it had to work for an extended period.
>>
>>108043149
>>108043237
Yeah it's an AMD thing then. If you're on Linux too then I'm 100% confident it's something about the fact that it's AMD. Only AMD on Linux had my AMD GPU and CPU making weird noises during inference
>>
If gemma3 is the "most capable model that runs on a single GPU" for completion and vision, what would the equivalent be for tools / agentic stuff?
Kimi seems like a good choice if you can run it, but I'm curious more on the low end of things like can be done with qwen. Is that still the most pragmatic model to use for conventional desktops not specifically geared for this?
>>
>>
>>108043286
probably because the windows drivers don't run the GPU hard enough to cause the coil whine. AI inference runs significantly faster on Linux. and you're delusional if you think nvidia cards don't do this too.
>>
>>
>>
File: screenshot-2026-02-02_23-12-12.png (112.8 KB)

112.8 KB PNG
>https://x.com/DAlistarh/status/2018341421976076317
>Happy to release Quartet II, a new method that pushes the frontier of 4-bit LLM training in NVFP4.
Fully-quantized pre-training in NVFP4 can now match FP8/FP16 quality much more closely, while maintaining full hardware acceleration!
>The key algorithmic insight is that stochastic rounding for unbiased gradients wastes bits. We propose a new quantizer called MS-EDEN that moves randomness (and variance) from FP4 values to the microscales, cutting quantization error by more than 2× while preserving unbiasedness.
>On the systems side, we have custom CUDA kernels for Blackwell GPUs that achieve up to 4.2× speedup over BF16, and 2.4× higher throughput in real 1B-parameter training. Key is a new post hoc range alignment trick avoids costly double tensor loads during re-quantization.
Seems like a win for local. This is the gptq/marlin guy I believe
>>
>>108032910
It's amazing that K2.5 can basically do everything that I test it on, from describing an Image, to transcribing text and even translating said text, but it sucks that even with all of these improvements, no LLM has gotten anywhere close to being a a good writer. Every single sloppy prose and annoying style imaginable is the best they can do, and it's just sad. When will we finally get models that can go beyond this constraint?
>>
stepfun is very good. running it on 2x rtx pro 6000s:
slot print_timing: id 0 | task 60809 |
prompt eval time = 923.40 ms / 736 tokens ( 1.25 ms per token, 797.05 tokens per second)
eval time = 34810.73 ms / 1276 tokens ( 27.28 ms per token, 36.66 tokens per second)
total time = 35734.14 ms / 2012 tokens
slot release: id 0 | task 60809 | stop processing: n_tokens = 39000, truncated = 0
srv update_slots: all slots are idle
kind of slow compared to minimax, but looking forward to running it on vllm and with mtp support where it should be very fast.
This is the real deal.
>>
>>
>>108044231
https://huggingface.co/stepfun-ai/Step-3.5-Flash-Int4/tree/main
Int4
>>
>>
>>
>>108044363
it actually is a lot quicker when I switched back to split-mode layers instead of row.
prompt eval time = 9702.60 ms / 42305 tokens ( 0.23 ms per token, 4360.17 tokens per second)
eval time = 27377.76 ms / 1616 tokens ( 16.94 ms per token, 59.03 tokens per second)
total time = 37080.36 ms / 43921 tokens
slot release: id 3 | task 0 | stop processing: n_tokens = 43920, truncated = 0
>>
>>
>>
File: 1759622038850522.png (2.2 MB)
2.2 MB PNG
AI Doomsissies are not going to be happy about this one
>>
>>108042145
>>108044196
ok motherfuckers you've convinced me, going to try it.
>>
>>
>>
>>
>>
>>
>>
>>
File: 1754384376930696.jpg (1.2 MB)

1.2 MB JPG
>>108044789
kek
>>
>>
how good are local models at English<->Japanese translations?
This is embarrassing, but I got in over my head with getting a jap roleplay partner, and I wanted my communications to be natural and not give away I'm a dumb foreigner. However, I can't rely on models to do anything lewd. Can a local model on 16gb vram handle JP translations that sound natural?
>>
File: 1743165216375907.png (41.2 KB)

41.2 KB PNG
>>108045266
>JP translations that sound natural
anon.....
>>
>>
File: shopping(6).jpg (80.9 KB)

80.9 KB JPG
Is Turing any gud for proompting at all?
>>
>>
>>
>>
>>
>>
>>
File: Hatsune Teto.png (1.3 MB)

1.3 MB PNG
>>
>>108045580
>based encouragement anon. However I think even if I spent every waking moment on subbed anime for 6 months I wouldn't be able to text communicate naturally. And I certainly wouldn't know kanji.
dunno maybe don't go local for this, and test some shit like en->jp->en to see what looks least fucked
probably kimi-k2.5 or opussy-4.5
>>
>>
>>
File: 1769161554002570.png (2.8 MB)

2.8 MB PNG
>>
>>108045842
I think I'll need to go local just so I can handle lewd things without the AI going into a panic
>>108045859
But Gemini can't do lewd, I assume
>>108045882
Japanese is really nuanced, and afaik there are numerous ways you can just "sound foreign" even if you're trying your damn best. Maybe they will be OK with that, but I see it as just adding friction.
>>
>>108045903
The best models today can't even reliably make english that sounds completely natural, why do you think they'd be any better at a language with far less training data and attention, one which is also stupid with what kind of context you should be leaving out at any given time? You're either going to give yourself away as a JSL or as a weirdo who runs his thoughts through a machine, pick which one is less embarrassing to you.
>>
File: abliteration_optimization.png (2.4 MB)

2.4 MB PNG
Continuing with the abliteration optimization thing. Today I've worked on the web interfaces for visualization.
>>
>>
>>108045932
>The best models today can't even reliably make english that sounds completely natural, why do you think they'd be any better at a language with far less training data and attention, one which is also stupid with what kind of context you should be leaving out at any given time? You're either going to give yourself away as a JSL or as a weirdo who runs his thoughts through a machine, pick which one is less embarrassing to you.
that's true, maybe he should hire a translator if it doesn't have to be real time
>>
>>108045806
prompt?
>>108045954
you said it creates a tiny lora for the targeted weights right? any reason we can't just save it as a peft adapter so we don't need 2 copies of the weights?
>>
>>
>>
File: Tetosday.png (869 KB)

869 KB PNG
>>108046563
>>108046563
>>108046563
>>
>>108046119
>>108046140
Replied in the new thread.
>>
File: 1723728499730432.jpg (99.7 KB)

99.7 KB JPG